I'm struggling with a simple task and after reading a lot of StackOverflow posts e searching on Pandas documentation I've decided to ask for help here.
Problem
I have a list of nested tuples which looks like this:
Terminal log of a list of nested tuples

And I need to create a Pandas DataFrame with a column for each inner tuple element. When I remove the last two elements of each inner tuple (e.g ((58, '2022-04-28', 85.0199966430664, 'BUY'), (67, '2022-05-11', 77.54000091552734, 'STOP BUY'))) I get the expected result:
DataFrame with expected result
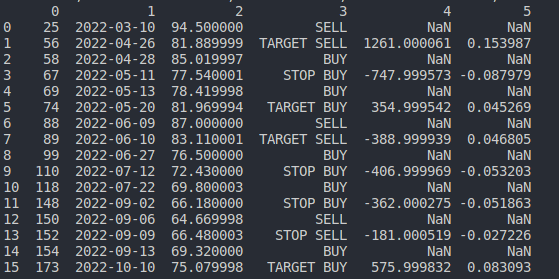
So far, so good.
But notice that I'm dealing with NaN values in the last two columns. Here's the point where it got tricky to me. When I add two values to each inner tupple (e.g ((58, '2022-04-28', 85.0199966430664, 'BUY', 8501.99966430664, 100), (67, '2022-05-11', 77.54000091552734, 'STOP BUY', -747.9995727539062, -0.08797925220982794))) I got a DataFrame where each NaN value of the last two columns are filled with the new values I've added as the image below shows: DataFrame with unexpected result
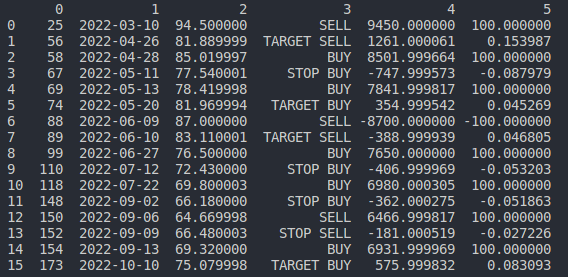
How can I manage to have a column for each item of the inner tuples?
My code looks like this:
# simply converting an existing dictionary into a DataFrame
final_report_df = pd.DataFrame.from_dict(final_report,orient="index")
# I'm using chain only to reduce the level of nested lists I had previously
prepare_data_to_df = list(chain.from_iterable(all_orders))
df_all_orders = pd.DataFrame(prepare_data_to_df, columns=["Id", "Date", "Price", "Label", "Profit/Loss ($)", "Profit/Loss (%)"]
df_all_orders.drop("Id", axis=1, inplace=True)
Given a tuple like this:
((58, '2022-04-28', 85.0199966430664, 'BUY', 8501.99966430664, 100), (67, '2022-05-11', 77.54000091552734, 'STOP BUY', -747.9995727539062, -0.08797925220982794))
As an expected result I want 7 columns:
| Date | Price | Label | Profit/Loss ($) | Profit/Loss (%) | Amount Invested | Stock Shares |
Date, Price, Label will be filled for the two tuples meanwhile Profit/Loss ($) and Profit/Loss (%) will be filled only in rows related with the second tuple. Finally, Stock Shares will be filled with the last value of the first tuple and Amount Invested with the value last but one of the first tuple.
I hope my explanation didn't get confused...
Thanks in advance.
CodePudding user response:
From what I understand, you have the following structure:
[
(
(A1, B1, C1, D1, Y, Z),
(A2, B2, C2, D2, W, X)
), ...
]
And you're trying to convert to a Dataframe with this structure:
A B C D W X Y Z
----------------------------------
A1 B1 C1 D1 NaN NaN Y Z
A2 B2 C2 D2 W X NaN NaN
I'm sure there are a few different ways to tackle that, I would be inclined to create two separate Dataframes, one for the first set of tuples one for the second, then do an outer merge.
The following worked when I tried it with a sample of your data:
# Create dictionaries from the first and second tuples, respectively
orders = {i: all_orders[i][0] for i in range(len(all_orders))}
stop_orders = {i: all_orders[i][1] for i in range(len(all_orders))}
# Convert dictionaries into DFs and give appropriate column names
orders_df = pd.DataFrame.from_dict(orders, orient="index")
orders_df.columns = ["ID", "Date", "Price", "Label", "Amount Invested", "Stock Shares"]
stop_orders_df = pd.DataFrame.from_dict(stop_orders, orient="index")
stop_orders_df.columns = ["ID", "Date", "Price", "Label", "Profit/Loss ($)", "Profit/Loss (%)"]
# Execute an outer merge so all columns are retained and columns that are in one DF but not in the other are filled with NA
all_orders_df = pd.merge(orders_df, stop_orders_df, how="outer")
Hope that helps! There may be more performant approaches if you have a lot of data, but the above should get the job done.