I am trying to creating python dictionary keys dynamically in order to serve the data into csv file but not getting anywhere so far. Here is my code:
import requests
from bs4 import BeautifulSoup
import csv
class ZiwiScraper:
results = []
headers = {
'authority': '99petshops.com.au',
'accept': 'text/html,application/xhtml xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en,ru;q=0.9',
'cache-control': 'max-age=0',
# Requests sorts cookies= alphabetically
# 'cookie': 'TrackerGuid=f5419f8d-632a-46b1-aa04-eed027d03e89; _ga=GA1.3.1385392550.1666770065; _gid=GA1.3.1560927430.1666770065',
'referer': 'https://www.upwork.com/',
'sec-ch-ua': '"Chromium";v="104", " Not A;Brand";v="99", "Yandex";v="22"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'cross-site',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.114 YaBrowser/22.9.1.1110 (beta) Yowser/2.5 Safari/537.36',
}
def fetch(self, url):
print(f'HTTP GET request to URL: {url}', end='')
res = requests.get(url, headers=self.headers)
print(f' | Status Code: {res.status_code}')
return res
def parse(self, html):
soup = BeautifulSoup(html, 'lxml')
titles = [title.text.strip() for title in soup.find_all('h2')]
low_prices = [low_price.text.split(' ')[-1] for low_price in soup.find_all('span', {'class': 'hilighted'})]
store_names = []
stores = soup.find_all('p')
for store in stores:
store_name = store.find('img')
if store_name:
store_names.append(store_name['alt'])
shipping_prices = [shipping.text.strip() for shipping in soup.find_all('p', {'class': 'shipping'})]
price_per_hundered_kg = [unit_per_kg.text.strip() for unit_per_kg in soup.find_all('p', {'class': 'unit-price'})]
other_details = soup.find_all('div', {'class': 'pd-details'})
for index in range(0, len(titles)):
try:
price_per_100_kg = price_per_hundered_kg[index]
except:
price_per_100_kg = ''
try:
lowest_prices = low_prices[index]
except:
lowest_prices = ''
for detail in other_details:
detail_1 = [pr.text.strip() for pr in detail.find_all('span', {'class': 'sp-price'})]
for idx, price in enumerate(detail_1):
self.results.append({
'title': titles[index],
'lowest_prices': lowest_prices,
f'lowest_price_{idx}': detail_1[idx],
'store_names': store_names[index],
'shipping_prices': shipping_prices[index],
'price_per_100_kg': price_per_100_kg,
})
# json_object = json.dumps(self.results, indent=4)
# with open("ziwi_pets_2.json", "w") as outfile:
# outfile.write(json_object)
def to_csv(self):
with open('ziwi_pets_2.csv', 'w') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=self.results[0].keys())
writer.writeheader()
for row in self.results:
writer.writerow(row)
print('Stored results to "ziwi_pets_2.csv"')
def run(self):
for page in range(1):
url = f'https://99petshops.com.au/Search?brandName=Ziwi Peak&animalCode=DOG&storeId=89/&page={page}'
response = self.fetch(url)
self.parse(response.text)
self.to_csv()
if __name__ == '__main__':
scraper = ZiwiScraper()
scraper.run()
Every time I run the script it gives me the above code I got ValueError: dict contains fields not in fieldnames: 'lowest_price_1'. csv file however generating with one entry only.
title,lowest_prices,lowest_price_0,store_names,shipping_prices,price_per_100_kg
Ziwi Peak Dog Air-Dried Free Range Chicken Recipe 1Kg,$57.75,$64.60,Woofers World, $9.95 shipping,$5.78 per 100g
I tried to output it as json just to see the data formation and it was also not as I expected.
[
{
"title": "Ziwi Peak Dog Air-Dried Free Range Chicken Recipe 1Kg",
"lowest_prices": "$57.75",
"lowest_price_0": "$64.60",
"store_names": "Woofers World",
"shipping_prices": " $9.95 shipping",
"price_per_100_kg": "$5.78 per 100g"
},
{
"title": "Ziwi Peak Dog Air-Dried Free Range Chicken Recipe 1Kg",
"lowest_prices": "$57.75",
"lowest_price_1": "$64.60",
"store_names": "Woofers World",
"shipping_prices": " $9.95 shipping",
"price_per_100_kg": "$5.78 per 100g"
},
{
"title": "Ziwi Peak Dog Air-Dried Free Range Chicken Recipe 1Kg",
"lowest_prices": "$57.75",
"lowest_price_2": "$64.95",
"store_names": "Woofers World",
"shipping_prices": " $9.95 shipping",
"price_per_100_kg": "$5.78 per 100g"
},
]
I expected something like this:
[
{
"title": "Ziwi Peak Dog Air-Dried Free Range Chicken Recipe 1Kg",
"lowest_prices": "$57.75",
"lowest_price_0": "$64.60",
"lowest_price_1": "$64.60",
"lowest_price_2": "$64.95",
"store_names": "Woofers World",
"shipping_prices": " $9.95 shipping",
"price_per_100_kg": "$5.78 per 100g"
},
]
Can anyone please help me out here? Thanks.
CodePudding user response:
You were creating csv header based only upon the first result, which didn't contained whole set of unique keys.
Change to_csv function to this to resolve your problem:
def to_csv(self):
key_list = list()
for key_list_for_one_element in [list(x.keys()) for x in self.results]:
key_list.extend(key_list_for_one_element)
key_list = set(key_list)
with open('ziwi_pets_2.csv', 'w') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=key_list)
writer.writeheader()
for row in self.results:
writer.writerow(row)
print('Stored results to "ziwi_pets_2.csv"')
CodePudding user response:
You need to pass as fieldnames all the keys any item in self.results might have. The error should go away if you just add that into your to_csv function
def to_csv(self):
fNames = list(set([k for r in self.results for k in r.keys()]))
fNames.sort(key=lambda r: (
-1*(int(r.replace('lowest_price_', '')) 1) if 'lowest_price_' in r else 0, r
), reverse=True)
with open('ziwi_pets_2.csv', 'w') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=fNames)
writer.writeheader()
for row in self.results:
writer.writerow(row)
print('Stored results to "ziwi_pets_2.csv"')
(The sort statement is optional - it's just to make sure the columns are in a certain order.)
As for this bit
I expected something like this
the for idx, price in enumerate(detail_1) in the parse function is appending a new line for every lowest_price_idx value of each detail. To get get them all in one line, change the outer loop to
for detail in other_details:
result_i = {
'title': titles[index],
'lowest_prices': lowest_prices,
'store_names': store_names[index],
'shipping_prices': shipping_prices[index],
'price_per_100_kg': price_per_100_kg,
}
detail_1 = [pr.text.strip() for pr in detail.find_all('span', {'class': 'sp-price'})]
for idx, price in enumerate(detail_1):
result_i[f'lowest_price_{idx}'] = detail_1[idx]
self.results.append(result_i)
Then, your csv output will go from
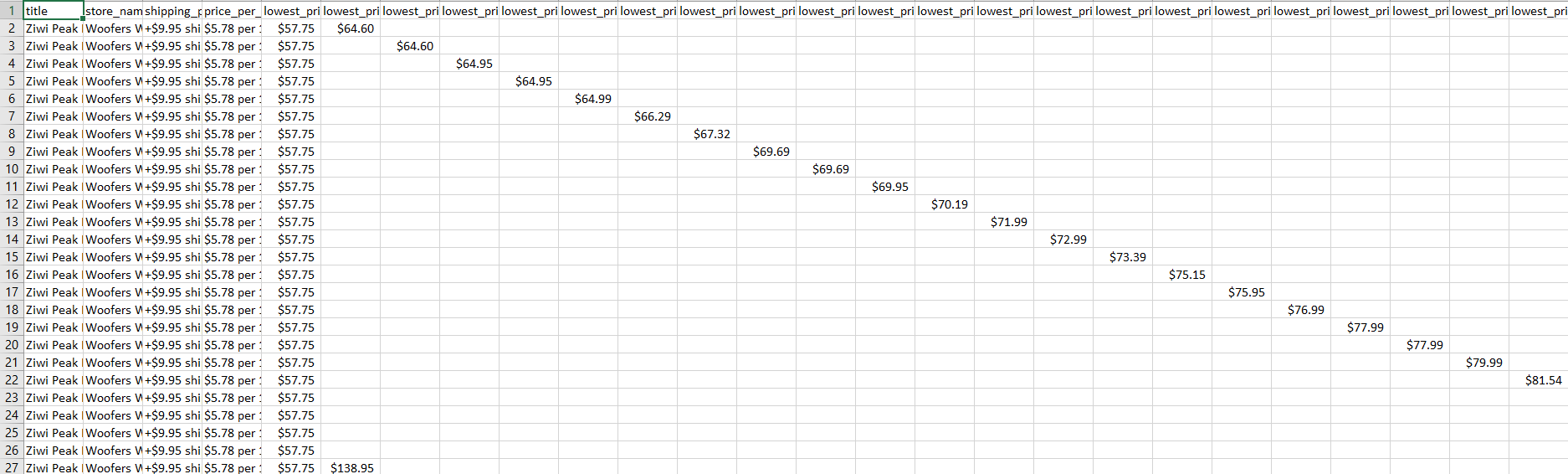 to
to
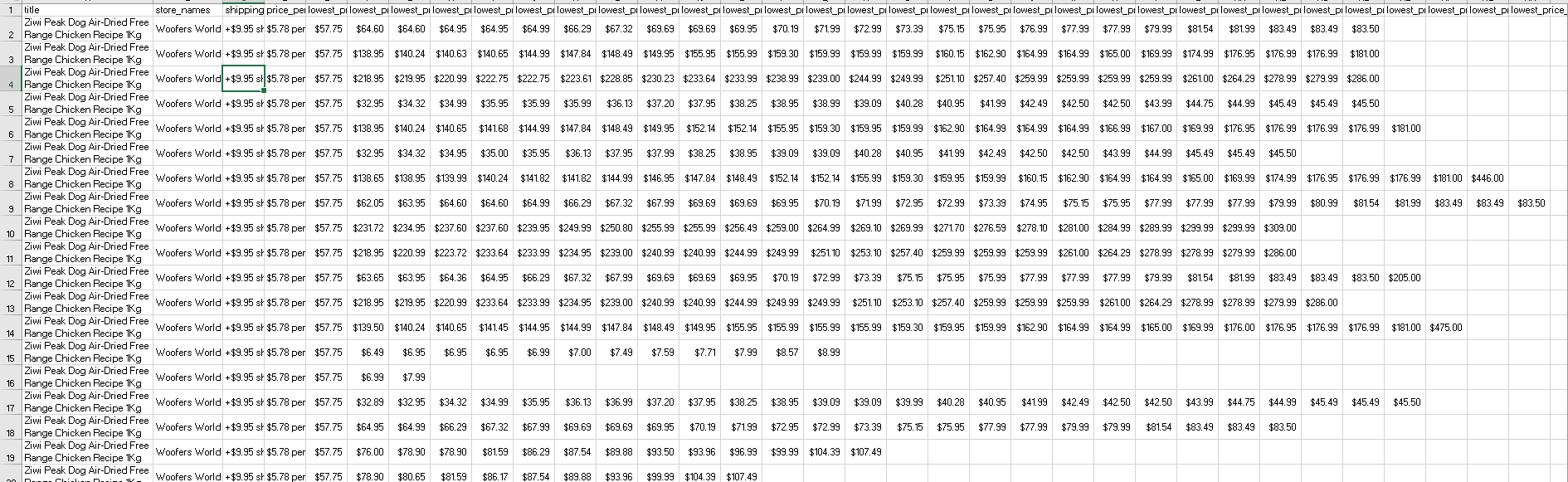
and you json would look, as expected
{
"title": "Ziwi Peak Dog Air-Dried Free Range Chicken Recipe 1Kg",
"lowest_prices": "$57.75",
"store_names": "Woofers World",
"shipping_prices": " $9.95 shipping",
"price_per_100_kg": "$5.78 per 100g",
"lowest_price_0": "$3.87",
"lowest_price_1": "$4.49",
"lowest_price_2": "$5.09",
"lowest_price_3": "$5.95",
"lowest_price_4": "$5.99"
}
(printed using print(json.dumps([r for r in scraper.results if len(r) == 10][0], indent=4)))