Lets say we have two strings
str1 = "021A,775U,000A,021A,1U2,206B,240,249,255B,260,263B,280,294,2U1,306B,336B,345,427,440,442,474,477,4U4,500,508,523,543L,580,584,772,802,P55,VB" ;
str2 = "772 240 802 P55 263B 1U2 VB";
and want to know if every substring of str2 splitted by " " is in str1.
Is there something "better" than doing this
string[] str1Arr = str1.Split(',');
foreach (var s in str2.Split(' '))
{
if (!str1Arr.Contains(s))
{
return false;
}
}
return true;
str2 would return true, while
str3 ="772 240 802 P55 263B 1U2 V";
would return false.
Edit:
Max length of str1 is ~1000 with all delimited strings being unique and sorted. Max lenght of str2 is ~700 (average 200) with substrings being unique but not sorted.
Here are some more strings:
"200B 201B 202 202B 203B 204B 205 205B 206 206B 207 207B 208 208B 209 209B 210 210B 211B 214B 216B 460 494 498 830 379"//false
"612 637 638 646 649 655 664 678 688 693 694 754 756 758 774 778 780 781 787 99R B58 RQW RRG RTJ RVI RVJ RVU RVV"//false
"255B 2U1 775U 336B P55 802"//true
"220 223 224 229 230 233 234 402 537 550 811 863 872 881 889 965 512L 516L 520L 521L 524L 526L 528L 581L 810L 812L 814L 816L 818L 830"//false
"255B"//true
CodePudding user response:
It depends on the length of the strings, but you could get a minor optimisation by using a HashSet to ensure that there are only unique entries in the first array
HashSet<string> str1Values = new HashSet<string>(str1.Split(','));
foreach (var s in str2.Split(' '))
{
if (!str1Values.Contains(s))
{
return false;
}
}
return true;
Or we can do the same in LINQ:
HashSet<string> str1Values = new HashSet<string>(str1.Split(','));
return str2.Split(' ').All(s => str1Values.Contains(s));
We can also use 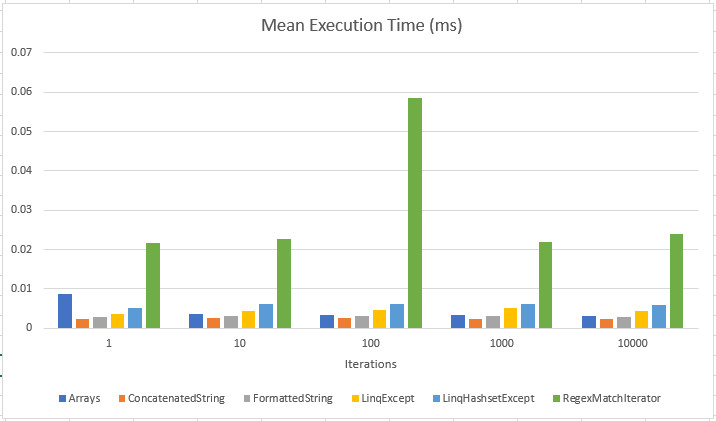
On to the actual testing, this time using the new comparison strings:
string str1 = "021A,775U,000A,021A,1U2,206B,240,249,255B,260,263B,280,294,2U1,306B,336B,345,427,440,442,474,477,4U4,500508,523,543L,580,584,772,802,P55,VB" ;
string str2 = "772 240 802 P55 263B 1U2 VB";
string str3 = "772 240 802 P55 263B 508 VB"; // false
string str4 = "200B 201B 202 202B 203B 204B 205 205B 206 206B 207 207B 208 208B 209 209B 210 210B 211B 214B 216B 460 494 498 830 379";//false
string str5 = "612 637 638 646 649 655 664 678 688 693 694 754 756 758 774 778 780 781 787 99R B58 RQW RRG RTJ RVI RVJ RVU RVV";//false
string str6 = "255B 2U1 775U 336B P55 802";//true
string str7 = "220 223 224 229 230 233 234 402 537 550 811 863 872 881 889 965 512L 516L 520L 521L 524L 526L 528L 581L 810L 812L 814L 816L 818L 830";//false
string str8 = "255B";//true
Run this fiddle: 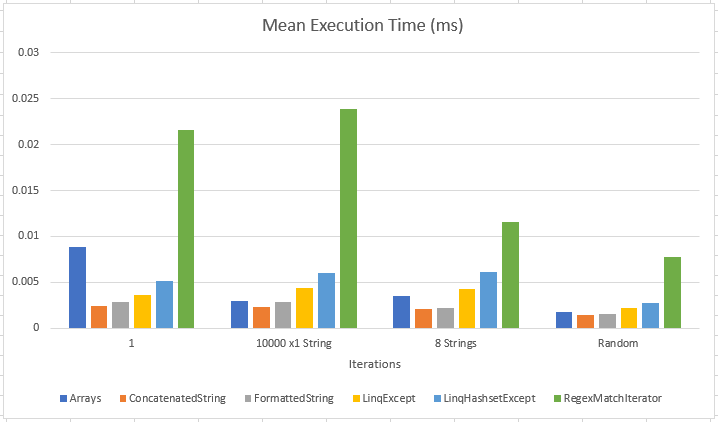
Overall ConcatenatedString still wins, but this time the margin is even smaller, and the FormattedString solution is still the most consistent, which might indicate that for a very large set of data, it could be the most reliable.
Also have a look at the original Array based solution, that is only marginally more expensive than the FormattedString but has a comparatively high degree of variance, which means this result set might have been lucky.
- The last test only had 10 iterations of each combination due to runtime execution constraints, so it's not the most reliable data.
I had dreams of generating a random set of terms that fit the patterns described and then injecting a random number of the terms but TBH i'm out of time, it was a fun adventure, but its chewed up my sunday and now its getting late for dinner.
When looking for performance tuning, you need to have some good metrics around what you are currently experiencing and a realistic idea of both what is acceptable and how much time you are willing to pay for this effort. As an example, I bet OP has already spent a number of hours on this task, add my 8 hours today and the collective hours of others who have read this post and considered it, then this solution is well over 12 hours cost to the team.
I always defer back to this 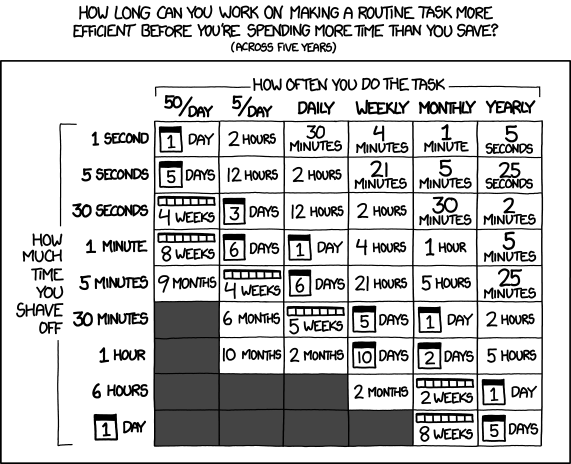
Don't forget the time you spend finding the chart to look up what you save. And the time spent reading this reminder about the time spent. And the time trying to figure out if either of those actually make sense. Remember, every second counts toward your life total, including these right now.
The difference between the Array method and the ConcatenatedString is still very marginal, you would need a very large dataset to really observe any difference that this implementation can provide.
We've spent over 12 hours, so if this makes your query run 5 seconds faster, and you run this over 5 times a day, then in 5 years you break even with the time you spend working on this issue vs the cumulative time the user would have spent waiting for the query to complete if you have done nothing.
When working with SQL and CLR functions, there are other optimisations that you can do in the SQL database that can significantly improve the performance, CLR functions are hard for SQL to optimise, generally for a query that involves this sort of data it is easy to assume that improvements in the rest of the structure of the query or evaluating other filtering constraints before this type of lookup would save more time than what we have saved here today.
A Final Thought...
If thestr1value is pretty consistent for all the items in the list, then an XML or JSON comparison inside the SQL can be far more efficient, you can reduce the cycles for each row by half by pre-formatting thestr1value as a constant variable for the query, but you lose any benefit to this if you try to pass that data across the boundary into CLR.If this is frequently queried data used in search functions, similar to tags in tweets and other social media posts, then there are better architectural solutions to this problem, the simplest of which is to create a table of the individual terms so we can index them. The good news about SQL is that this implementation detail can be entirely managed in the database with triggers, that way the application and business domain logic do not need to be affected by this structural optimisation.