So I'm using Puppeteer to scrap text from social media, I want to only scrap the text from a post, when I use the chrome developer tool to read what is the class name of the div which contains the text, it always displays a different class name when I reload the page but stay on the same post(see image)
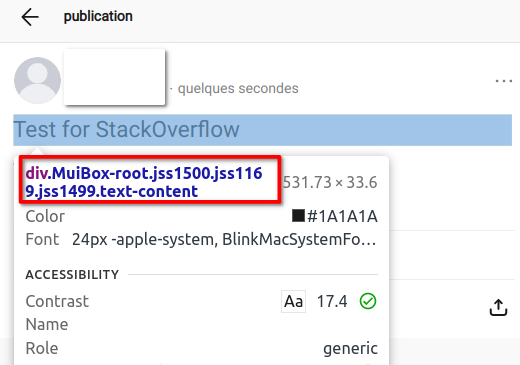
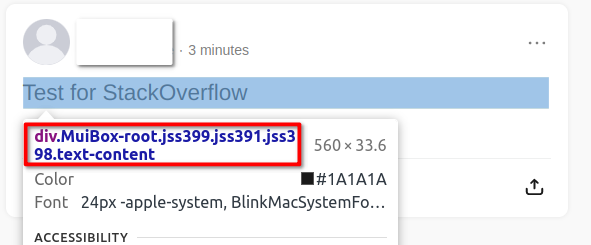
But I noticed that the div class name always ends with .text-content, is there a way to select a div with only the end of the class name?
I tried to use the $ selector like this :
document.querySelectorAll("[class$='text-content']")
And yes it finds the correct div but if I try to use .textContent or .innerText it doesn't work and it returns undefined.
I also tried to select all divs from the developer console and then see if I could use the index of this div but it turns out that the index also changes every time I reload the page
What I wrote in the developer console :
document.querySelectorAll('div')
and then it gave me an array of divs but as I said I can't use that if the index changes every time.
CodePudding user response:
Why your solution won't work
Document.querySelectorAll will return an HTMLCollection (an array-like element) so accessing to Node.textContent property will result in undefined, you should either use Document.querySelector or get the first index separately.
Get individual element
Working example for demonstration:
document.querySelectorAll("[class$='text-content']")[0].textContent
const content = document.querySelector("[class$='text-content']").textContent;
console.log(content)<div >This is the content</div>or
document.querySelector("[class$='text-content']").textContent
const content = document.querySelectorAll("[class$='text-content']")[0].textContent;
console.log(content)<div >This is the content</div>Get all the matching elements
Also if you want to get all of the you can do a loop over the elements provided by querySelectorAll and the with the help of Array#forEach.
const elements = document.querySelectorAll("[class$='text-content']");
Array.from(elements).forEach(element => console.log(element.textContent))<div >This is the content</div>
<div >This is the content 2</div>
<div >This is the content 3</div>
<div >This is the content 4</div>
<div >This is the content 5</div>
<div >This is the content 6</div>CodePudding user response:
You can use getElementsByClassName:
document.getElementsByClassName('text-content');
But do notice this returns a HTMLCollection. So you'll have to use accessors or iterate to get the elements contents:
const elements = document.getElementsByClassName('text-content');
// using acessor
console.log(elements[0].innerText);
console.log(elements[1].innerText);
// or iterating
for (const element of elements)
console.log(element.innerText);<div >aaa</div>
<div >bbb</div>CodePudding user response:
You are actually quite close.
The classes are denoted by the . and these can be strung together. So those random values you stung together are dynamic classes.
For usage on that querySelector you can have a look here:
https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelector
Armed with that knowledge you can easily pick up the elements you need.
// Since you need only the one class:
var elements = document.querySelectorAll(".text-content");
// Then you can get all of the elements matching.
for (let i = 0; i < elements. Length; i ) {
// And easily do what you want with each.
// Like getting or setting content.
elements[i].innerText = "updated content";
}<div >
dummy content
</div>
<div >
dummy content
</div>
<div >
dummy content
</div>