I am scraping a website and would like to find specific content based on style, so I do
soup.find_all('style')
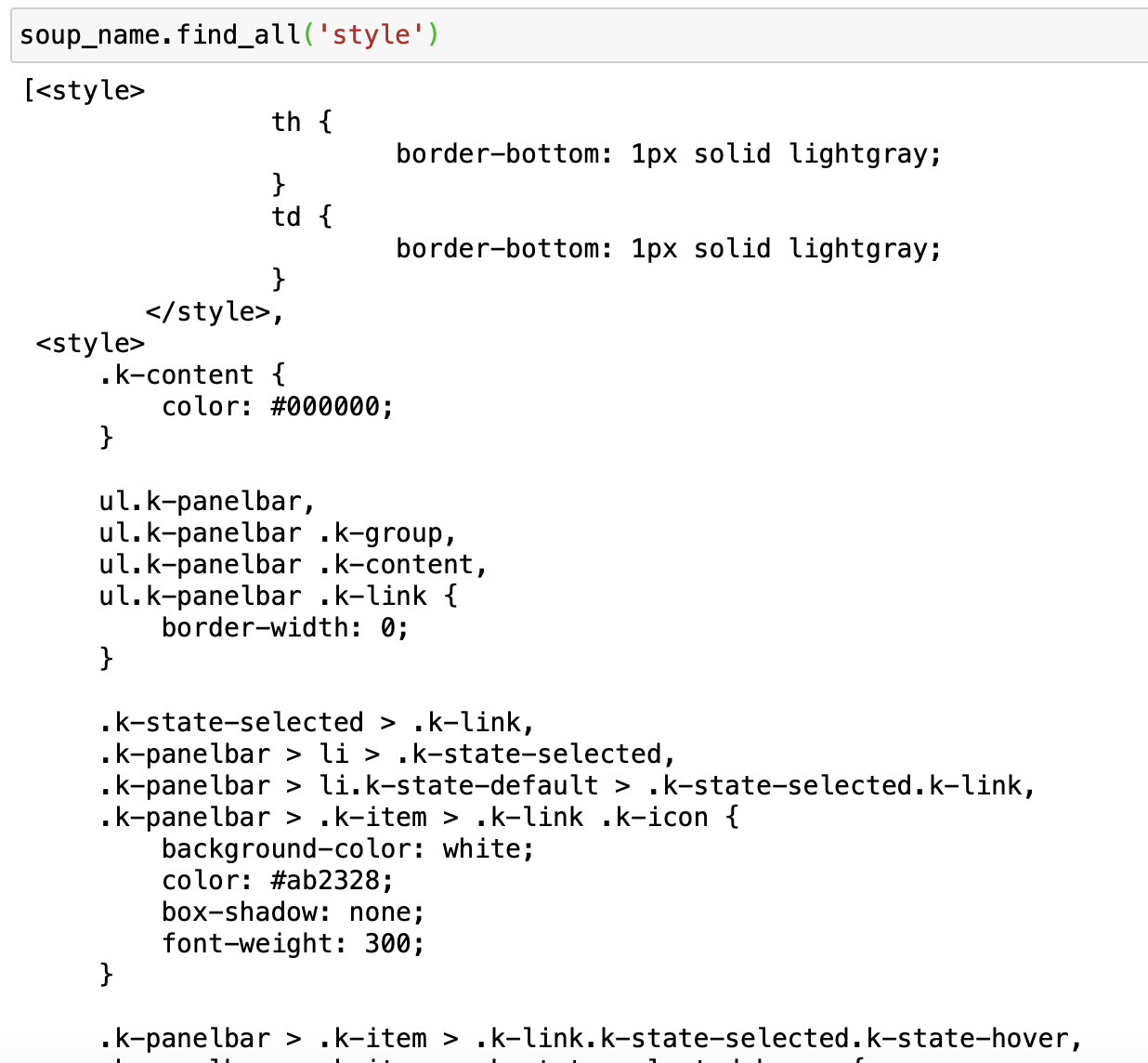
and it does return some result/text, but once I use .text soup_name.find_all('style')[0].text to extract the text, it returns an empty string
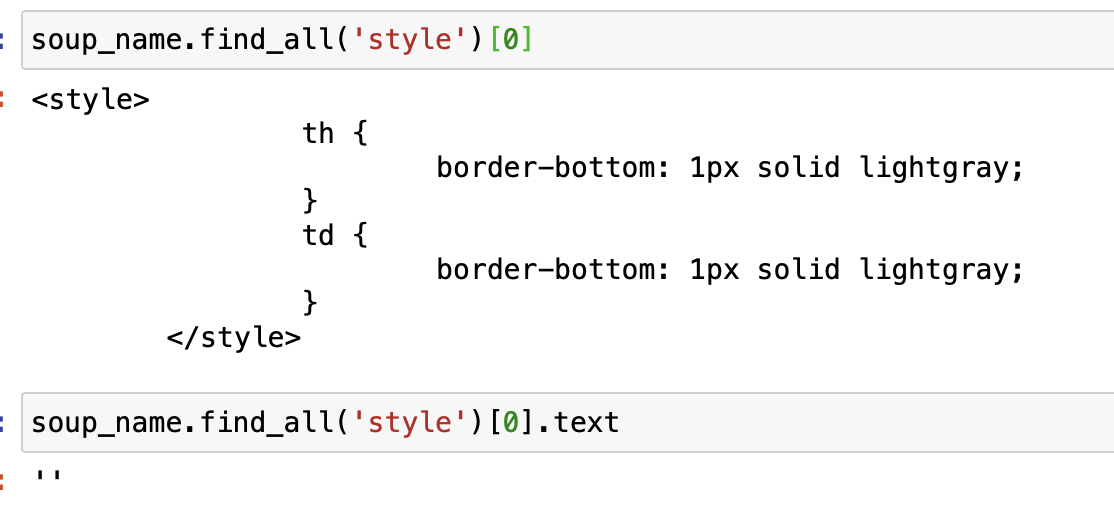
What can I do to extract the text in the style tag?
Thanks in advanced!
CodePudding user response:
Try .contents[0]:
from bs4 import BeautifulSoup
html_doc = """\
<style>
th { border: none; }
</style>"""
soup = BeautifulSoup(html_doc, "html5lib")
print(soup.find("style").contents[0])
Prints:
th { border: none; }
CodePudding user response:
If nothing else, you can just use
str(soup.find('style')).strip()[7:-8].strip()
to get the stylesheet as one string. If you want to know more about parsing the css, you might like to check this out.