I have hundreds of word documents that needs to be processed but need to organized them first by versions in subfolders.
I basically get a drop of these word documents within a single folder and need to automate the organization moving forward before I get nuts.
So I have a script that basically creates a folder with the same name of the file and moves the file inside that folder, this part is done.
Now I need to go into each subfolder, and get the document version from within the first word page of each document, then create a sub-folder withe version number and move the word file into that subfolder.
The structure should be as follows (taking two folders as examples):
(Folder) Test
(Subfolder) 12.0
Test.docx
(Folder) Test1
(Subfolder) 13.0
Test1.docx
Luckily I was able to figure it out that "doc.paragraphs[6].text" will always return the version information in a single line as follows:
>>> doc.paragraphs[6].text
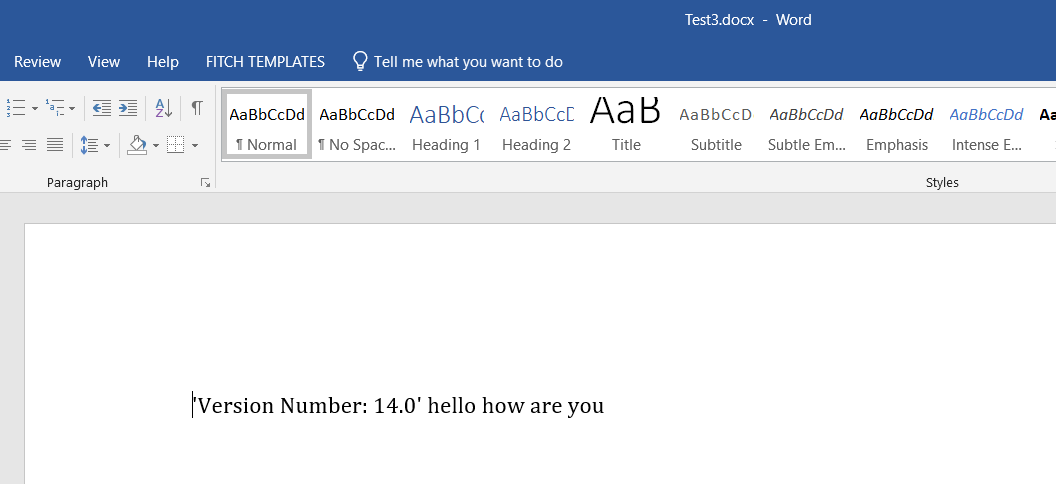
'Version Number: 12.0'
Would appreciate if someone can point me out to the right direction.
This is the script I have so far:
#!/usr/bin/env python3
import glob, os, shutil, docx, sys
folder = sys.argv[1]
#print(folder)
for file_path in glob.glob(os.path.join(folder, '*.docx')):
new_dir = file_path.rsplit('.', 1)[0]
#print(new_dir)
try:
os.mkdir(os.path.join(folder, new_dir))
except WindowsError:
# Handle the case where the target dir already exist.
pass
shutil.move(file_path, os.path.join(new_dir, os.path.basename(file_path)))
CodePudding user response:
So you have a script that creates a folder name being the file name and moves the file inside that folder. This part is done. OK.
Now you know how to get the document version from within the first word page of each document you need to create a sub-folder with this version number and move the word file into that sub-folder. This can be done using the same code as before replacing:
new_dir = file_path.rsplit('.', 1)[0]
with
document_dir = os.path.dirname(file_path)
document_name = os.path.basename(file_path)
# check if the document is already in the right directory:
assert os.path.basename(document_dir) == document_name.rsplit('.', 1)[0]
# here comes: doc = some_function_getting_the_doc_object(file_path)
doc_version_tuple = doc.paragraphs[6].text.rsplit(': ', 1)
# check if doc_version_tuple has the right content:
assert doc_version_tuple[0] == 'Version Number'
doc_version = doc_version_tuple[1]
new_dir = os.path.join(document_dir, doc_version)
Notice that you can also do both of the two steps in one run over the list of full path document names.
Notice further that running the script you posted in your question twice without the check:
assert os.path.basename(document_dir) != document_name.rsplit('.', 1)[0]
giving an Error if the script was already run and the documents are already in folders with the document name will destroy what you already achieved and you will need to write another script to reverse it.
The above is the reason why it would be a good idea to have a backup copy of all the documents you can use to re-create the directory with the documents in case something goes wrong. And ... it is generally a good idea to have always a backup copy if you work on files especially when using a self-written script.
CodePudding user response:
Please see below the complete solution to your requirement.
Note: To know about re.search go through 
After Execution