I have two MS Access SQL queries which I want to convert into PySpark. The queries look like this (we have two tables Employee and Department):
UPDATE EMPLOYEE INNER JOIN [DEPARTMENT] ON
EMPLOYEE.STATEPROVINCE = [DEPARTMENT].[STATE_LEVEL]
SET EMPLOYEE.STATEPROVINCE = [DEPARTMENT]![STATE_ABBREVIATION];
UPDATE EMPLOYEE INNER JOIN [DEPARTMENT] ON
EMPLOYEE.STATEPROVINCE = [DEPARTMENT].[STATE_LEVEL]
SET EMPLOYEE.MARKET = [DEPARTMENT]![MARKET];
CodePudding user response:
Test dataframes:
from pyspark.sql import functions as F
df_emp = spark.createDataFrame([(1, 'a'), (2, 'bb')], ['EMPLOYEE', 'STATEPROVINCE'])
df_emp.show()
# -------- -------------
# |EMPLOYEE|STATEPROVINCE|
# -------- -------------
# | 1| a|
# | 2| bb|
# -------- -------------
df_dept = spark.createDataFrame([('bb', 'b')], ['STATE_LEVEL', 'STATE_ABBREVIATION'])
df_dept.show()
# ----------- ------------------
# |STATE_LEVEL|STATE_ABBREVIATION|
# ----------- ------------------
# | bb| b|
# ----------- ------------------
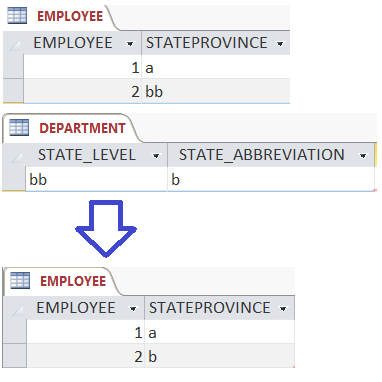
Running your SQL query in Microsoft Access does the following:
In PySpark, you can get it like this:
df = (df_emp.alias('a')
.join(df_dept.alias('b'), df_emp.STATEPROVINCE == df_dept.STATE_LEVEL, 'left')
.select(
*[c for c in df_emp.columns if c != 'STATEPROVINCE'],
F.coalesce('b.STATE_ABBREVIATION', 'a.STATEPROVINCE').alias('STATEPROVINCE')
)
)
df.show()
# -------- -------------
# |EMPLOYEE|STATEPROVINCE|
# -------- -------------
# | 1| a|
# | 2| b|
# -------- -------------
First you do a left join. Then, select.
The select has 2 parts.
- First, you select everything from
df_empexcept for "STATEPROVINCE". - Then, for the new "STATEPROVINCE", you select "STATE_ABBREVIATION" from
df_dept, but in case it's null (i.e. not existent indf_dept), you take "STATEPROVINCE" fromdf_emp.
For your second query, you only need to change values in the select statement:
df = (df_emp.alias('a')
.join(df_dept.alias('b'), df_emp.STATEPROVINCE == df_dept.STATE_LEVEL, 'left')
.select(
*[c for c in df_emp.columns if c != 'MARKET'],
F.coalesce('b.MARKET', 'a.MARKET').alias('MARKET')
)
)