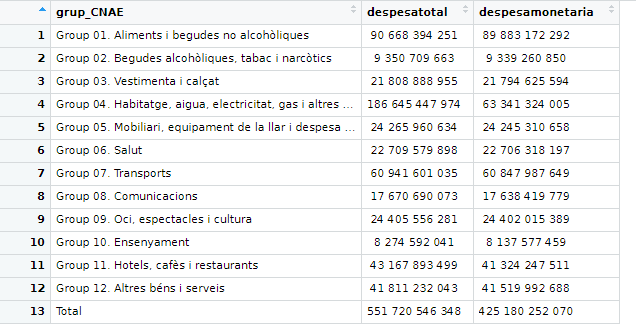
I need to divide columns despesatotal and despesamonetaria by the row named Total:
CodePudding user response:
Lets suppose your data set is df.
# 1) Delete the last row
df <- df[-nrow(df),]
# 2) Build the desired data.frame [combining the CNAE names and the proportion columns
new.df <- cbind(grup_CNAE = df$grup_CNAE,
100*prop.table(df[,-1],margin = 2))
Finally, rename your columns. Be careful with the matrix or data.frame formats, because sometimes mathematical operations may suppose a problem. If you you use dput function in order to give us a reproducible example, the answer would be more accurate.
CodePudding user response:
Here is a way to get it done. This is not the best way, but I think it is very readable.
Suppose this is your data frame:
mydf = structure(list(grup_CNAE = c("A", "B", "C", "D", "E", "Total"
), despesatotal = c(71, 93, 81, 27, 39, 311), despesamonetaria = c(7,
72, 36, 22, 73, 210)), row.names = c(NA, -6L), class = "data.frame")
mydf
# grup_CNAE despesatotal despesamonetaria
#1 A 71 7
#2 B 93 72
#3 C 81 36
#4 D 27 22
#5 E 39 73
#6 Total 311 210
To divide despesatotal values with its total value, you need to use the total value (311 in this example) as the denominator. Note that the total value is located in the last row. You can identify its position by indexing the despesatotal column and use nrow() as the index value.
mydf |> mutate(percentage1 = despesatotal/despesatotal[nrow(mydf)],
percentage2 = despesamonetaria /despesamonetaria[nrow(mydf)])
# grup_CNAE despesatotal despesamonetaria percentage1 percentage2
#1 A 71 7 0.22829582 0.03333333
#2 B 93 72 0.29903537 0.34285714
#3 C 81 36 0.26045016 0.17142857
#4 D 27 22 0.08681672 0.10476190
#5 E 39 73 0.12540193 0.34761905
#6 Total 311 210 1.00000000 1.00000000
CodePudding user response:
library(tidyverse)
Sample data
# A tibble: 11 x 3
group despesatotal despesamonetaria
<chr> <int> <int>
1 1 198 586
2 2 186 525
3 3 202 563
4 4 300 562
5 5 126 545
6 6 215 529
7 7 183 524
8 8 163 597
9 9 213 592
10 10 175 530
11 Total 1961 5553
df %>%
mutate(percentage_total = despesatotal / last(despesatotal),
percentage_monetaria = despesamonetaria/ last(despesamonetaria)) %>%
slice(-nrow(.))
# A tibble: 10 x 5
group despesatotal despesamonetaria percentage_total percentage_monetaria
<chr> <int> <int> <dbl> <dbl>
1 1 198 586 0.101 0.106
2 2 186 525 0.0948 0.0945
3 3 202 563 0.103 0.101
4 4 300 562 0.153 0.101
5 5 126 545 0.0643 0.0981
6 6 215 529 0.110 0.0953
7 7 183 524 0.0933 0.0944
8 8 163 597 0.0831 0.108
9 9 213 592 0.109 0.107
10 10 175 530 0.0892 0.0954