I have two .csv files in the same directory with the same number of columns and I want to combine them into one file, but keep just one header from the first file. The file name is always different, only the prefix remains the same:
orderline_123456.csv
Order_number,Quantity,Price
100,10,25.3
101,15,30.2
orderline_896524.csv
Order_number,Quantity,Price
102,20,12.33
103,3,3.4
The output file should be like:
file_load.csv
Order_number,Quantity,Price
100,10,25.3
101,15,30.2
102,20,12.33
103,3,3.4
This was already in the shell script file, because since now I needed to take only one file, but now I have to merge two files:
awk '(NR-1)%2{$1=$1}1' RS=\" ORS=\" orderline_*.csv >> file_to_load.csv
I tried changing it into
awk 'FNR == 1 && NR != 1 {next} (NR-1)%2{$1=$1}1' RS=\" ORS=\" orderline_*.csv >> file_to_load.csv
but I get the header twice in the output.
Could you please help me? How exactly should the command look like? I need to keep how it was defined before.
Thank you!
CodePudding user response:
You're looking for
awk 'NR == 1 || FNR > 1' file ...
NR is the count of all records seen, and
FNR is the record number of the current file.
CodePudding user response:
Sometimes the solution is divide the task in easy steps
1. Get the first line which is the header and store as variable
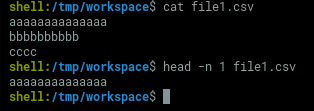
header=$(head -n 1 file1.csv)
2. Get all lines of a file except the first one
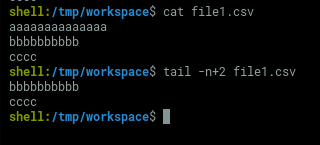
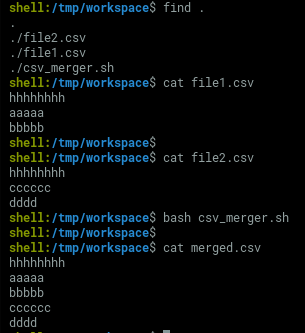
3. Concat the header and n bodies
csv_merger.sh
header=$(head -n 1 file1.csv)
body1=$(tail -n 2 file1.csv)
body2=$(tail -n 2 file2.csv)
echo "$header" > merged.csv
echo "$body1" >> merged.csv
echo "$body2" >> merged.csv
Result
You could extend this script to handle more files
CodePudding user response:
Using csvstack from the handy csvkit package is one way to merge CSV files with the same columns:
$ csvstack orderline_123456.csv orderline_896524.csv > file_load.csv