I have a dataframe games_h. This is just a snippet of the table but it has many teams and is sorted by date, team, game number. I am trying to create a weighted rolling average grouped by the team. I would like the most recent game to be weighted more than two games ago. So the weights would be (Game_1 * 1 Game_2 *2)/3 or weights equal to 1 with same ratio so weights = c(1-.667, .667).
dput(games_h)
structure(list(GameId = c(16, 16, 37, 37, 57, 57), GameDate = structure(c(17905,
17905, 17916, 17916, 17926, 17926), class = "Date"), NeutralSite = c(0,
0, 0, 0, 0, 0), AwayTeam = c("Virginia Cavaliers", "Virginia Cavaliers",
"Florida State Seminoles", "Florida State Seminoles", "Syracuse Orange",
"Syracuse Orange"), HomeTeam = c("Boston College Eagles", "Boston College Eagles",
"Boston College Eagles", "Boston College Eagles", "Boston College Eagles",
"Boston College Eagles"), Team = c("Virginia Cavaliers", "Boston College Eagles",
"Florida State Seminoles", "Boston College Eagles", "Syracuse Orange",
"Boston College Eagles"), Home = c(0, 1, 0, 1, 0, 1), Score = c(83,
56, 82, 87, 77, 71), AST = c(17, 6, 12, 16, 11, 13), TOV = c(10,
8, 9, 13, 11, 11), STL = c(5, 4, 4, 6, 6, 5), BLK = c(6, 0, 4,
4, 1, 0), Rebounds = c(38, 18, 36, 33, 23, 23), ORB = c(7, 4,
16, 10, 7, 6), DRB = c(31, 14, 20, 23, 16, 17), FGA = c(55, 57,
67, 55, 52, 45), FGM = c(33, 22, 28, 27, 29, 21), X3FGM = c(8,
7, 8, 13, 11, 9), X3FGA = c(19, 25, 25, 21, 26, 22), FTA = c(14,
9, 24, 28, 15, 23), FTM = c(9, 5, 18, 20, 8, 20), Fouls = c(16,
12, 25, 20, 19, 19), Game_Number = 1:6, Count = c(1, 1, 1, 1,
1, 1)), class = c("grouped_df", "tbl_df", "tbl", "data.frame"
), row.names = c(NA, -6L), groups = structure(list(HomeTeam = "Boston College Eagles",
.rows = structure(list(1:6), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -1L), .drop = TRUE))
Here is an example output of the score column.
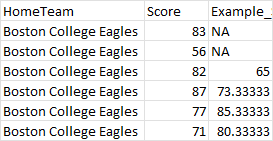
Here is my failed attempt. The function work correctly but I cannot apply it to the entire dataframe by group.
weighted_avg<-function(x, wt1, wt2) {
rs1 = rollsum(x,1,align = "right")
rs2 = rollsum(x,2,align = "right")
rs1=rs1[-1]
rs3 = rs2 - rs1
weighted_avg= ((rs3 * wt2) (rs1*wt1))/(wt1 wt2)
return(weighted_avg)
}
weighted_avg(csum$Score_Y, 2, 1)
apply(csum$Score_Y , 2, weighted_avg, wt1 = 2, wt2=1)
test<-csum %>%
group_by(Team)%>%
group_map(across(c(Score:Fouls), weighted_avg(.x$Team, 2, 1) ))
test<-csum %>%
group_by(Team)%>%
group_walk(across(c(Score:Fouls),weighted_avg(.~,2,1) ))
CodePudding user response:
Here are some notes about the code:
- I used
slider::slide_dblfunction. First we specify the vector for which we would like to compute the moving averageScore. - As we need a sliding window of length 2, I used
.beforeargument inslide_dblto use the previous value and a current value to be used for calculating moving average. - Also I set
.completeargument toTRUEto makes sure to only calculate moving average when we have a previous value. In other word we don't have any moveing average in first row.
For more info check the documentation for slider package.
library(tidyverse)
library(slider)
df %>%
group_by(HomeTeam) %>%
summarise(Example = c(NA, slide_dbl(Score, .before = 1, .complete = TRUE,
.f = ~ (.x[1] * 1 .x[2] * 2) / 3)))
`summarise()` has grouped output by 'HomeTeam'. You can override using the `.groups` argument.
# A tibble: 7 × 2
# Groups: HomeTeam [1]
HomeTeam Example
<chr> <dbl>
1 Boston College Eagles NA
2 Boston College Eagles NA
3 Boston College Eagles 65
4 Boston College Eagles 73.3
5 Boston College Eagles 85.3
6 Boston College Eagles 80.3
7 Boston College Eagles 73
If it is going to calculate moving average for all numeric columns you could try:
df %>%
group_by(HomeTeam) %>%
summarise(across(where(is.numeric), ~ c(NA, slide_dbl(., .before = 1, .complete = TRUE,
.f = ~ (.x[1] * 1 .x[2] * 2) / 3)))) %>%
ungroup()
`summarise()` has grouped output by 'HomeTeam'. You can override using the `.groups` argument.
# A tibble: 7 × 21
HomeTeam GameId NeutralSite Home Score AST TOV STL BLK Rebounds ORB DRB FGA FGM
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Boston C… NA NA NA NA NA NA NA NA NA NA NA NA NA
2 Boston C… NA NA NA NA NA NA NA NA NA NA NA NA NA
3 Boston C… 16 0 0.667 65 9.67 8.67 4.33 2 24.7 5 19.7 56.3 25.7
4 Boston C… 30 0 0.333 73.3 10 8.67 4 2.67 30 12 18 63.7 26
5 Boston C… 37 0 0.667 85.3 14.7 11.7 5.33 4 34 12 22 59 27.3
6 Boston C… 50.3 0 0.333 80.3 12.7 11.7 6 2 26.3 8 18.3 53 28.3
7 Boston C… 57 0 0.667 73 12.3 11 5.33 0.333 23 6.33 16.7 47.3 23.7
# … with 7 more variables: X3FGM <dbl>, X3FGA <dbl>, FTA <dbl>, FTM <dbl>, Fouls <dbl>,
# Game_Number <dbl>, Count <dbl>