I want to get the last record from the duplicate records and want the non-duplicate records also.
As depicted in the below image I want to get row number 4, 5, 7 and 9 in my output.
](https://i.stack.imgur.com/EZ2fF.png)](https://img.codepudding.com/202211/0cfe6f652925450c869cb80c939d8255.png)
Here, In the below image the ** Main table** was shown. From which I have to concat first two columns and then from that new column I need the last row of duplicate records and the non-duplicate rows also.
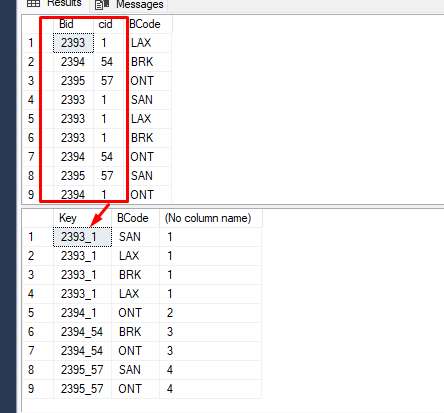
I have tried with the given below SQL code.
DECLARE @dense_rank_demo AS TABLE (
Bid INT,
cid INT,
BCode NVARCHAR(10)
);
INSERT INTO @dense_rank_demo(Bid,cid,BCode)
VALUES(2393,1,'LAX'),(2394,54,'BRK'),(2395,57,'ONT'),(2393,1,'SAN'),(2393,1,'LAX'),(2393,1,'BRK'),(2394,54,'ONT'),(2395,57,'SAN'),(2394,1,'ONT');
SELECT * FROM @dense_rank_demo;
SELECT
CONCAT([Bid],'_',[cid]) as [Key],BCode,DENSE_RANK() over( order by CONCAT([Bid],'_',[cid]))
from @dense_rank_demo
CodePudding user response:
The issue here is the ordering of the values within the result set. If you had a specific order to use, this would be fairly straightforward - however, you are relying on dense_rank() to consistently and reliably returning the same values for those in the table. If we could use, for example, the alpha sort on the BCode column then it would be simple to use a CTE and get the last/first one:
with [drd] as
(
select
concat([Bid],'_',[cid]) as [Key],
BCode,
dense_rank() over(partition by concat([Bid],'_',[cid]) order by Bcode desc) as [dr]
from @dense_rank_demo
)
select *
from [drd]
where dr = 1
As the order of dense_rank() is not guaranteed in your code, I'm not sure that this is feasible in a scalable way.
See this for more information about reliably sorted results: how does SELECT TOP works when no order by is specified?
CodePudding user response:
you need one row per BID i.e the latest one, But you have not specified the logic of the last row. Usually, last row is the most recent added one and so there is usually a timestamp that can be used to pick the latest row where there are duplicates.
The code below uses the Bcode as a part of the
order bycalause, that means it will automatically pick the row that has the lowest alphabet order, which not be the row that you expect unless thats how you define the most recent row. You would in general need to play with theorder byclause based on your needs but the timestamp makes most senserow_number()generates the values 1-n based on the partition by, incase there is a tie, and you need both rows, then you need to use thedense_rankinstead. Based on your needs you can adjust that
with main as (
select
concat(Bid, cid) as key,
row_number() over(partition by concat(Bid, cid) order by Bcode) as rank_
from <table_name>
)
select * from main where rank_ = 1