The general form of the equation is
Sector ~ Beta_0 Beta_1*absMkt Beta_2*sqMkt
where Sector are the daily stock returns of each of the 12 sectors i.e AUTO ; IT ; REALTY ; BANK ; ENERGY ; FINANCIAL SERVICES ; FMCG ; INFRASTRUCTURE ; SERVICES ; MEDIA ; METAL and PHARMA.
Beta_0 is the intercept; Beta_1 is the coefficient of absolute market return; Beta_2 is the coefficient of the squared market return.
For each sector, I would like to run linear regression, where I want to extract the coefficients Beta_1 and Beta_2 if the corresponding p-value is less than 0.05 and store it.
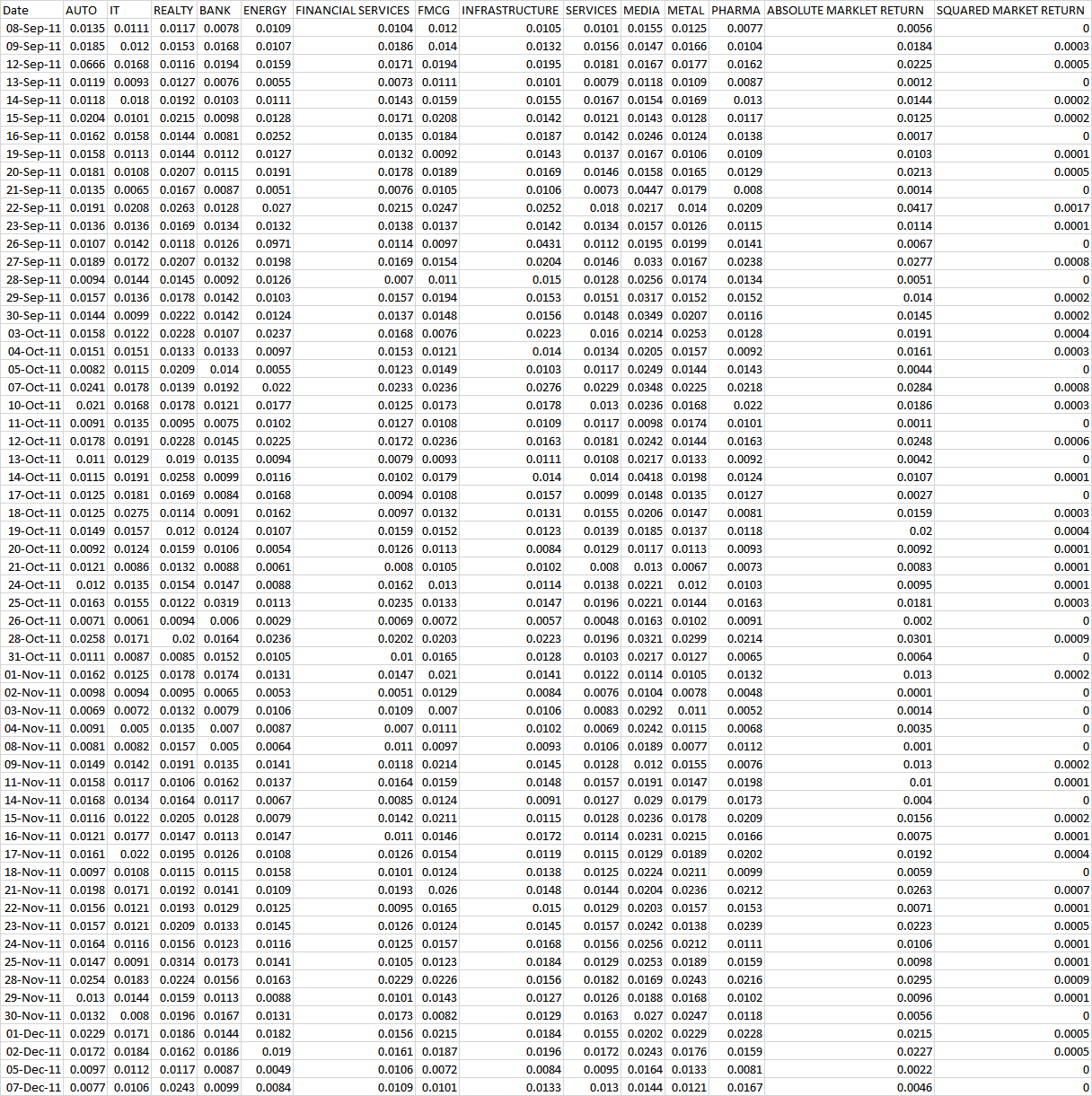
Sample data is stated below.
It is also available for download from my google drive location
Code that I have tried from my end, but not getting the result
# Reading the data
Returns <- read.csv("Week_1_CSV.CSV", header = TRUE, stringsAsFactors = FALSE)
# Splitting the Data into Sector and Market Returns
Sector_Returns <- Returns[,2:13]
Market_Returns <- Returns[,14:15]
# Defining the number of sectors
nc <- ncol(Sector_Returns)
# Creating a matrix with zero value to store the coefficient values and their corresponding p-values
Beta_1 <- Beta_2 <- p_1 <- p_2 <- matrix(0, 1, nc) # coefs and p values
# Converting the Sectoral Returns into a Matrix named "Sect_Ret_Mat"
Sect_Ret_Mat <- as.matrix(Sector_Returns)
head(Sect_Ret_Mat)
# Converting the Market Returns into a Matrix named "Mkt_Ret_Mat"
Mkt_Ret_Mat <- as.matrix(Market_Returns)
head(Mkt_Ret_Mat)
#### Without Loop ##############
mode1_lm <- lm(Sect_Ret_Mat[,1] ~ Mkt_Ret_Mat[,1] Mkt_Ret_Mat[,2] )
summary(mode1_lm)
# Extracting the p-value
coef(summary(mode1_lm))[2, 4] ## p-value corresponding to Beta_1
coef(summary(mode1_lm))[3, 4] ## p-value corresponding to Beta_2
# Extracting the Coefficient
coef(mode1_lm)[[2]] ## Coeficient corresponding to Beta_1
coef(mode1_lm)[[3]] ## Coeficient corresponding to Beta_2
##############################################################################
#### WithLoop ##############
for (i in 1:nc) {
for (j in 1:nc) {
if (i != j) {
mode1_lm <- lm(Sect_Ret_Mat[,i] ~ Mkt_Ret_Mat[,1] Mkt_Ret_Mat[,2] )
p_0[i,j] <- coef(summary(mode1_lm))[2, 4]
p_1[i,j] <- coef(summary(mode1_lm))[3, 4]
if
(p_0[i, j] < 0.05)
Beta_0[i,j] <- coef(mode1_lm)[[2]]
if
(p_1[i, j] < 0.05)
Beta_1[i,j] <- coef(mode1_lm)[[3]]
}
}
}
Beta_0
Beta_1
CodePudding user response:
As a general rule, I don't download datasets from a link. You should try to make a small example that can be easily run on anyone's computer. When running a bunch of regressions for different groups, I find it easiest to keep everything in one dataframe and avoid loops. The general workflow goes: 1) nest data by group, 2) run regression for each group, 3) use broom to make the coefficients into a nice table, 4) unnest the model coefficients into a table. Here is an example using mtcars. I show how to run a regression for each group of cyl.
library(tidyverse)
mtcars |>
nest(data = -cyl) |>
mutate(mod = map(data, ~lm(mpg~wt hp, data = .x)),
summ = map(mod, broom::tidy)) |>
select(-data, -mod) |>
unnest(summ)
#> # A tibble: 9 x 6
#> cyl term estimate std.error statistic p.value
#> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 6 (Intercept) 32.6 5.57 5.84 0.00428
#> 2 6 wt -3.24 1.37 -2.36 0.0776
#> 3 6 hp -0.0222 0.0202 -1.10 0.333
#> 4 4 (Intercept) 45.8 4.79 9.58 0.0000117
#> 5 4 wt -5.12 1.60 -3.19 0.0128
#> 6 4 hp -0.0905 0.0436 -2.08 0.0715
#> 7 8 (Intercept) 26.7 3.66 7.28 0.0000158
#> 8 8 wt -2.18 0.721 -3.02 0.0117
#> 9 8 hp -0.0137 0.0107 -1.27 0.229
CodePudding user response:
Melt your data long, and apply a helper function each sector:
- Set dataframe
wk1to data.table, and melt long
library(data.table)
setDT(wk1)
wk1 = melt(
data = wk1[, id:=.I],
id = c("id", "Date", "ABSOLUTE MARKLET RETURN", "SQUARED MARKET RETURN"),
variable.name = "sector"
)
- Write helper functiont that runs model and returns beta and p.value in list
f <- function(v,a,s) {
cf = summary(lm(v~a s))$coefficients[-1,]
list(est = cf[,1],pvalue=cf[,4])
}
- Apply
fto each sector
wk1[, f(value, `ABSOLUTE MARKLET RETURN`, `SQUARED MARKET RETURN`), sector]
Output:
sector beta pvalue
1: AUTO 0.71847599 1.837679e-02
2: AUTO -7.44556841 3.921574e-01
3: IT 0.33384211 2.878851e-02
4: IT -1.69884185 6.970822e-01
5: REALTY 0.19224293 3.128459e-01
6: REALTY 0.63655626 9.084056e-01
7: BANK 0.72886921 4.544867e-06
8: BANK -15.07590018 6.835331e-04
9: ENERGY 0.30568300 5.611571e-01
10: ENERGY -0.42252869 9.780039e-01
11: FINANCIAL SERVICES 0.46149507 1.940130e-04
12: FINANCIAL SERVICES -2.72192333 4.238560e-01
13: FMCG 0.38259697 1.398654e-02
14: FMCG -0.45504587 9.180342e-01
15: INFRASTRUCTURE 0.28891493 1.845572e-01
16: INFRASTRUCTURE 0.03244222 9.958937e-01
17: SERVICES 0.49497910 2.098375e-06
18: SERVICES -6.52723131 2.036243e-02
19: MEDIA 0.10040065 7.554367e-01
20: MEDIA 0.26014494 9.779231e-01
21: METAL 0.45139509 1.576446e-02
22: METAL -6.87462275 1.991497e-01
23: PHARMA 0.39993847 1.781434e-02
24: PHARMA -0.74201727 8.772388e-01