I'm trying to group values of below list in a dataframe based on Style,Gender and Region but with
values filled down.
My cuurent attempt gets a dataframe without style and region filled down. Not sure if it is good approach or would better
to manipulate the list lst
import pandas as pd
lst = [
['Tee','Boy','East','12','11.04'],
['Golf','Boy','East','12','13'],
['Fancy','Boy','East','12','11.96'],
['Tee','Girl','East','10','11.27'],
['Golf','Girl','East','10','12.12'],
['Fancy','Girl','East','10','13.74'],
['Tee','Boy','West','11','11.44'],
['Golf','Boy','West','11','12.63'],
['Fancy','Boy','West','11','12.06'],
['Tee','Girl','West','15','13.42'],
['Golf','Girl','West','15','11.48']
]
df1 = pd.DataFrame(lst, columns = ['Style','Gender','Region','Units','Price'])
df2 = df1.groupby(['Style','Region','Gender']).count()
Current output (content of df2)
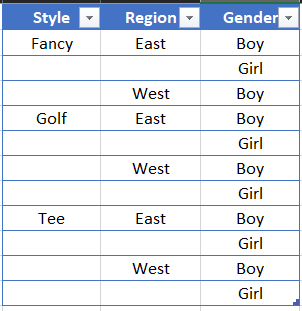
output I'm looking for
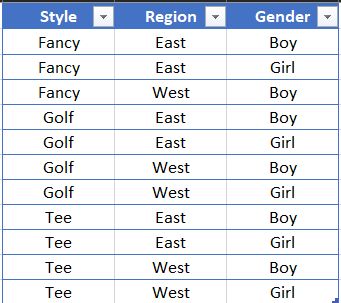
CodePudding user response:
You just need to use reset_index that will reset back to normal
df2.reset_index(inplace=True)