This is the Google Drive 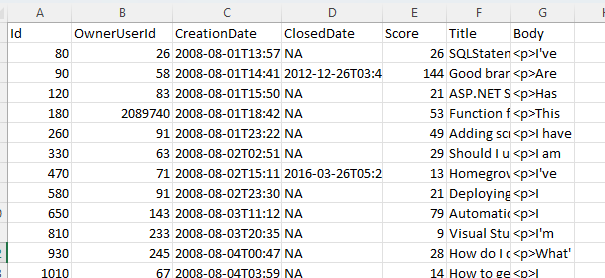
But when I read it with PySpark, it just messes up. I think it's because of the Body column, which is a long and complex HTML string. Does you guy have any idea how to fix it? I've already changed the delimiter option but it didn't work.
import pyspark
from pyspark.sql import *
from pyspark.sql.functions import *
spark = SparkSession.builder.master("local[*]").getOrCreate()
questionDf = spark.read \
.format('csv')\
.option("header", "true") \
.load("Questions.csv")
questionDf.select("*").filter(col("Id").isNotNull()).limit(100).show()
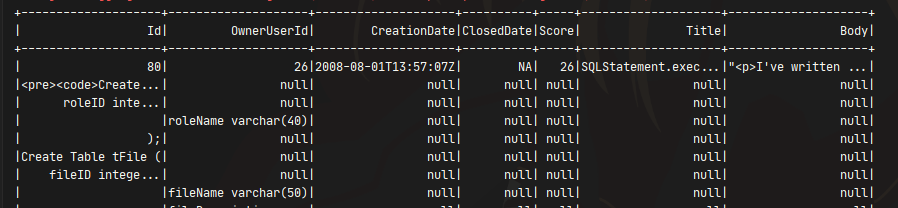
CodePudding user response:
You need two more options.
# When csv include newlines, parse 1 record that span across multiple lines
.option('multiLine', 'true')
# escape char that is used within quote-wrapped column.
# ex: "hello ""xxx""!" => each side of xxx should have literal 1 double quote.
.option('escape', '"')