I have an CSV file of having data I want to convert into JSON format but I get issue about the formation.
Data input in csv file:
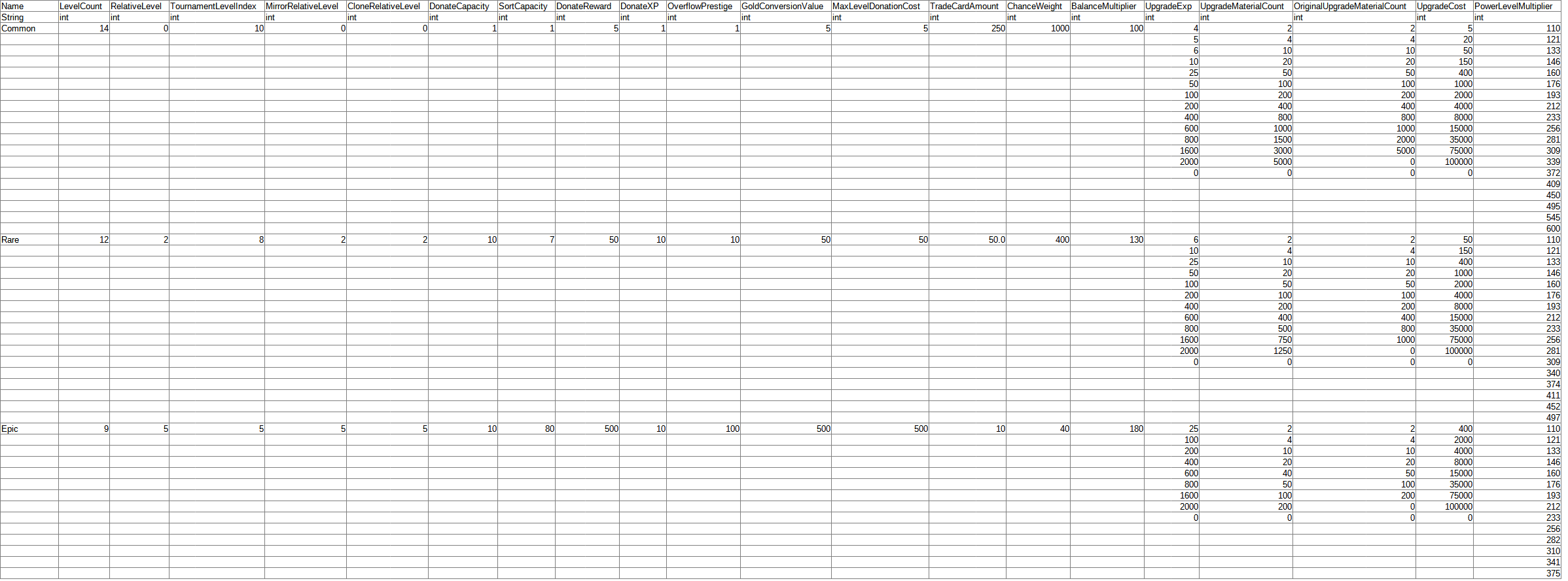
Full CSV: rarities.csv
I have tried this code but it doesn't get the desired result.
Here is the code :
import pandas as pd
df = pd.read_csv(r'rarities.csv')
df.to_json(r'rarities.json', orient='records')
properties name case doesn't matter
The data format I want in JSON:
[
{
"name": "Common",
"level_count": 14,
"relative_level": 0,
"tournament_level_index": 10,
"mirror_relative_level": 0,
"clone_relative_level": 0,
"donate_capacity": 1,
"sort_capacity": 1,
"donate_reward": 5,
"donate_xp": 1,
"overflow_prestige": 1,
"gold_conversion_value": 5,
"max_level_donation_cost": 5,
"trade_card_amount": 250,
"chance_weight": 1000,
"balance_multiplier": 100,
"upgrade_exp": [4, 5, 6, 10, 25, 50, 100, 200, 400, 600, 800, 1600, 2000, 0],
"upgrade_material_count": [2, 4, 10, 20, 50, 100, 200, 400, 800, 1000, 1500, 3000, 5000, 0],
"original_upgrade_material_count": [2, 4, 10, 20, 50, 100, 200, 400, 800, 1000, 2000, 5000, 0, 0],
"upgrade_cost": [5, 20, 50, 150, 400, 1000, 2000, 4000, 8000, 15000, 35000, 75000, 100000, 0],
"power_level_multiplier": [110, 121, 133, 146, 160, 176, 193, 212, 233, 256, 281, 309, 339, 372, 409, 450, 495, 545, 600]
},
{
"name": "Rare",
"level_count": 12,
"relative_level": 2,
"tournament_level_index": 8,
"mirror_relative_level": 2,
"clone_relative_level": 2,
"donate_capacity": 10,
"sort_capacity": 7,
"donate_reward": 50,
"donate_xp": 10,
"overflow_prestige": 10,
"gold_conversion_value": 50,
"max_level_donation_cost": 50,
"trade_card_amount": 50,
"chance_weight": 400,
"balance_multiplier": 130,
"upgrade_exp": [6, 10, 25, 50, 100, 200, 400, 600, 800, 1600, 2000, 0],
"upgrade_material_count": [2, 4, 10, 20, 50, 100, 200, 400, 500, 750, 1250, 0],
"original_upgrade_material_count": [2, 4, 10, 20, 50, 100, 200, 400, 800, 1000, 0, 0],
"upgrade_cost": [50, 150, 400, 1000, 2000, 4000, 8000, 15000, 35000, 75000, 100000, 0],
"power_level_multiplier": [110, 121, 133, 146, 160, 176, 193, 212, 233, 256, 281, 309, 340, 374, 411, 452, 497]
},
{
"name": "Epic",
"level_count": 9,
"relative_level": 5,
"tournament_level_index": 5,
"mirror_relative_level": 5,
"clone_relative_level": 5,
"donate_capacity": 10,
"sort_capacity": 80,
"donate_reward": 500,
"donate_xp": 10,
"overflow_prestige": 100,
"gold_conversion_value": 500,
"max_level_donation_cost": 500,
"trade_card_amount": 10,
"chance_weight": 40,
"balance_multiplier": 180,
"upgrade_exp": [25, 100, 200, 400, 600, 800, 1600, 2000, 0],
"upgrade_material_count": [2, 4, 10, 20, 40, 50, 100, 200, 0],
"original_upgrade_material_count": [2, 4, 10, 20, 50, 100, 200, 0, 0],
"upgrade_cost": [400, 2000, 4000, 8000, 15000, 35000, 75000, 100000, 0],
"power_level_multiplier": [110, 121, 133, 146, 160, 176, 193, 212, 233, 256, 282, 310, 341, 375]
}
]
full JSON: rarities.json
thanks for help.
CodePudding user response:
you can use:
df = df.drop(0) #delete first row. We will not use.
df['Name'] = df['Name'].ffill() #fillna in name column with first values until change
dfv = df.pivot_table(index='Name',aggfunc=list) #pivot table by name and put items to list
dfv = dfv.applymap(lambda x: [i for i in x if str(i) != 'nan']) #remove nans in lists
dfv = dfv.applymap(lambda x: x[0] if len(x)==1 else x) #if list lenght ==1, convert to string
dfv = dfv.applymap(lambda x: np.nan if x==[] else x) #convert empty lists to nan
dfv = dfv.reset_index()
final_json = dfv.to_dict('records')