I'm currently trying to extract information from lots of PDF forms such as this:
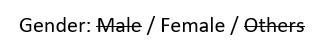
The text 'female' should be extracted here. So contrary to my title, I'm actually trying to extract text with no strikethroughs rather than text that with strikethroughs. But if I can identify which words with strikethroughs, I can easily identify the inverse.
Gaining inspiration from this post, I came up with this set of codes:
import os
import glob
from pdf2docx import parse
from docx import Document
lst = []
files = glob.glob(os.getcwd() r'\PDFs\*.pdf')
for i in range(len(files)):
filename = files[i].split('\\')[-1].split('.')[-2]
parse(files[i])
document = Document(os.getcwd() rf'\PDFs\{filename}.docx')
for p in document.paragraphs:
for run in p.runs:
if run.font.strike:
lst.append(run.text)
os.remove(os.getcwd() rf'\PDFs\{filename}.docx')
What the above code does is to convert all my PDF files into word documents (docx), and then search through the word documents for text with strikethroughs, extract those text, then delete the word document.
As you may have rightfully suspected, this set of code is very slow and inefficient, taking about 30s to run on my sample set of 4 PDFs with less than 10 pages combined.
I don't believe this is the best way to do this. However, when I did some research online, pdf2docx extracts data from PDFs using PyMuPDF, but yet PyMuPDF do not come with the capability to recognise strikethroughs in PDF text. How could this be so? When pdf2docx could perfectly convert strikethroughs in PDFs into docx document, indicating that the strikethroughs are being recognised at some level.
All in all, I would like to seek advice on whether or not it is possible to extract text with strikethroughs in PDF using Python. Thank you!
CodePudding user response:
Disclaimer: I am the author of borb, the library suggested in this answer
Ultimately, the exact code will end up varying depending on how strikethrough is implemented in your PDF. Allow me to clarify:
A PDF document (typically) has no notion of structure. So while we may see a paragraph of text, made up of several lines of text, a PDF (for the most part) just contains rendering instructions.
Things like:
- Go to X, Y
- Set the current font to Helvetica-Bold
- Set the current color to black
- Draw the letter "H"
- Go to X, Y (moving slightly to the right this time)
- Draw the letter "e"
- etc
So in all likelihood, the text that is striked through is not marked as such in any meaningful way.
I think there are 2 options:
- PDF has the concept of annotations. These are typically pieces of content that are added on top of a page. These can be extra text, geometric figures, etc. There is a specific annotation for strikethrough.
- It might be an annotation, but a geometric figure (in this case a line) that simply appears over the text.
- It might be a drawing instruction (inside the page content stream that is) that simply renders a black line over the text.
Your PDF might contain one (or more) of these, depending on which software initially created the strikethrough.
You can identify all of these using borb.
What I would do (in pseudo-code):
- Extend
SimpleTextExtraction(this is the main class inborbthat deals with extracting text from a PDF) - Whenever this class sees an event (this is typically the parser having finished a particular instruction) you can check whether you saw a text-rendering instruction, or a line-drawing instruction. Keep track of text, and keep track of lines (in particular their bounding boxes).
- When you have finished processing all events on a page, get all the annotations from the page, and filter out strikethrough annotations. Keep track of their bounding boxes.
- From the list of
TextRenderEventobjects, filter out those whose bounding box overlaps with: either a line, or a strikethrough bounding box - Copy the base algorithm for rebuilding text from these events
CodePudding user response:
If these strikethroughs in fact are annotations, PyMuPDF offers a simple and extremely fast solution: On a page make a list of all strikethrough annotation rectangles and extract the text "underneath" them. Or, similarly, look at keywords you are interested in (like "male", "female") and look if any is covered by a strikethrough annot.
# strike out annotation rectangles
st_rects = [a.rect for a in page.annots(types=[fitz.PDF_ANNOT_STRIKE_OUT])]
words = page.get_text("words") # the words on the page
for rect in st_rects:
for w in words:
wrect = fitz.Rect(w[:4]) # rect of the word
wtext = w[4] # word text
if wrect.intersects(rect):
print(f"{wtext} is strike out")
# the above checks if a word area intersects a strike out rect
# B/O mostly sloppy strike out rectangle definitions the safest way.
# alternatively, simpler:
for rect in st_rects:
print(page.get_textbox(rect (-5, -5, 5, 5)), "is striked out")
# here I have increased the strike out rect by 5 points in every direction
# in the hope to cover the respective text.