I am studying scraping to improve my skills. I'm scraping a news site, and it takes 4 minutes to get the HTML a element. The reason for the long processing time is unknown. Is there any way to increase the processing time?
#sauce
from bs4 import BeautifulSoup
with open('News_20221211.html',encoding="UTF-8") as f:
soup = BeautifulSoup(f, 'html.parser’)
tag=soup.select_one("#content div div div:nth-of-type(8) div div div div div div div:nth-of-type(1) div div:nth-of-type(1) div div a")
my research Increasing the number of "divs" increased the processing time.
tag=soup.select_one("#content div div div:nth-of-type(8) div div div”)
# processing time is 7sec
tag=soup.select_one("#content div div div:nth-of-type(8) div div div div")
# processing time is 17sec
tag=soup.select_one("#content div div div:nth-of-type(8) div div div div")
# processing time is 80sec
tag=soup.select_one("#content div div div:nth-of-type(8) div div div div div div div:nth-of-type(1) div div:nth-of-type(1) div div a")
# processing time is 240sec
Thank you for your prompt reply.
I use select_one and aim to create an environment where multiple news sites can be scraped simply by changing the conditions.
I've captured the HTML I'm having trouble with. I will attach it.
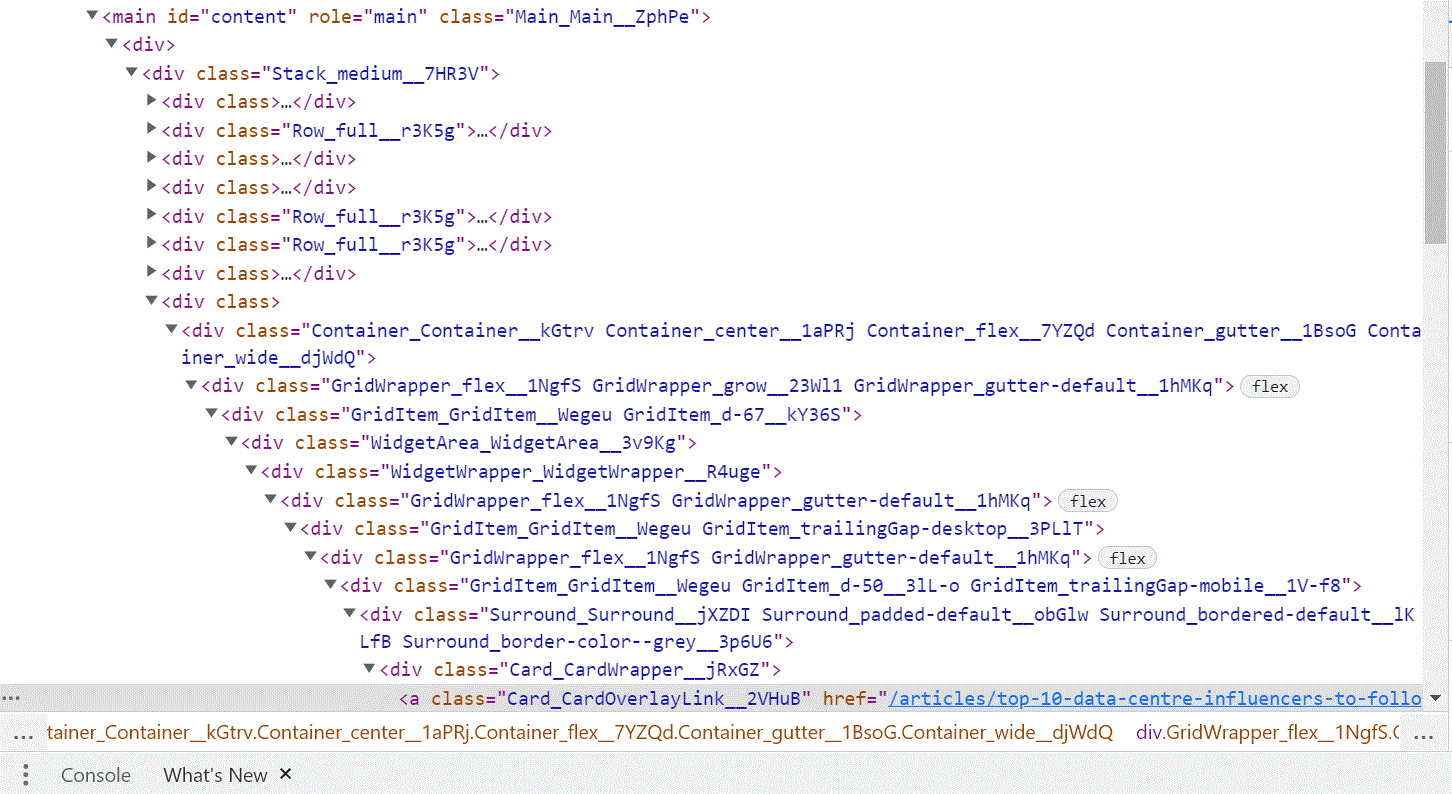
CodePudding user response:
Maybe you could use a faster parser? The html.parser that you're using in your code is relatively slow compared to other parsers such as html5lib and lxml. You could try using one of these parsers instead and see if it improves your processing time.
You might also try a different scraping method. Instead of using select_one, you could try other methods such as find or find_all. These methods might be faster, but I'm not completely sure.
CodePudding user response:
No one likes to type from an image, so please take a minute to read Why should I not upload images of code/data/errors? for why.
However, it is a very specific path to an element, so I would recommend to change your strategy of how to select elements. Ask yourself what is realy needed to make the path specific enough and what could be skipped.
The element is part under a <h2> with string Lists, that´s parent container is the previous sibling of the one of your element, so you can go with:
soup.select_one('h2:-soup-contains-own("Lists")').find_parent('div',{'class':''}).find_next_sibling().a
Cause I am not sure what is your intension, there is also the option to change the source may https://datacentremagazine.com/top10/all will give you an easier entrypoint.
Example
import requests
from bs4 import BeautifulSoup
url = 'https://datacentremagazine.com/'
soup = BeautifulSoup(requests.get(url).text)
soup.select_one('h2:-soup-contains-own("Lists")').find_parent('div',{'class':''}).find_next_sibling().a
Output
<a href="/articles/top-10-data-centre-influencers-to-follow-on-linkedin"></a>