Let me show with an example, I have this dataframe:
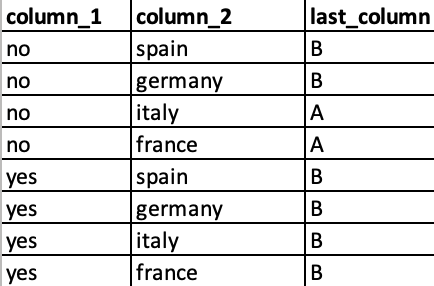
I want to end up with to this dataframe: (so I group by "column_1" and "last_column" and I aggregate by "column_2" to get the items as a list)

If you notice, when column_1 = 'yes' it doesn't appear that row, SINCE THE LENGTH OF THE RESULT IS 1.
I'm able to filter and aggregate as a list separately, but not both together...
df.groupby(
['column_1', 'last_column']
)['column_2'].agg(list).filter(lambda x : len(x)<2)
I'm getting the following error:

Dataframe:
import pandas as pd
data = {'column_1': ['no', 'no', 'no', 'no', 'yes', 'yes', 'yes', 'yes'],
'column_2': ['spain', 'france', 'italy', 'germany', 'spain', 'france', 'italy', 'germany'],
"last_column": ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B']}
df = pd.DataFrame.from_dict(data)
CodePudding user response:
You can try:
df_out = df.groupby(["column_1", "last_column"])["column_2"].agg(list)
df_out = df_out.groupby(level=0).filter(lambda y: len(y) > 1)
print(df_out.reset_index())
Prints:
column_1 last_column column_2
0 no A [italy, germany]
1 no B [spain, france]
Dataframe used:
column_1 column_2 last_column
0 no spain B
1 no france B
2 no italy A
3 no germany A
4 yes spain B
5 yes france B
6 yes italy B
7 yes germany B
CodePudding user response:
How about this?:
df2 = df.groupby(
['column_1', 'last_column'], as_index=False
)['column_2'].agg(list)
df2['len'] = df2['column_2'].apply(lambda x : len(x))
df2 = df2[df2['len']<=2]
df2