Im creating a Database from two sources , the sources are as follows
Create Table table_name1(Column_A VARCHAR(50), Column_B int, Column_C VARCHAR(50), Column_D VARCHAR(50));
Insert Into table_name1 Values
('A1',5,'C1','D1'),
('A1',23,'C2',null),
('A2',2,'C2','D1'),
('A12',23,'C2',null),
('A2',23,'C2',null),
('A12',12,'D2','C1');
Create Table table_name2(Column_A VARCHAR(50), Column_B int, Column_C VARCHAR(50), Column_D VARCHAR(50));
Insert Into table_name2 Values
('A1',5,'C1','D1'),
('A1',23,'C2',null),
('A1',21,'C2',null),
('A2',2,'C2','D1'),
('A2',34,'C2','D1'),
('A21',23,'C2','D1'),
('A2',23,'C2','D2'),
('A12',12,'D2','C1'),
('A12',23,'C2',null),;
Now i would like to union these two sources and generate ID's based on the business logic but at the same time i would like to know which data source is data coming from in a separate column 'table1' if it is from table1 and 'table2' if it is from table2 and if it is a common data then 'table1 & table2'
So far i wrote as follows
with t1 as(
select * from table_name1
union
select * from table_name2)
select dense_rank() over ( order by Column_B) as id_1,
dense_rank() over(order by t1.Column_A,t1.Column_C,t1.Column_D) as id_2, t1.Column_A,t1.Column_B,t1.Column_C, t1.Column_D
from t1
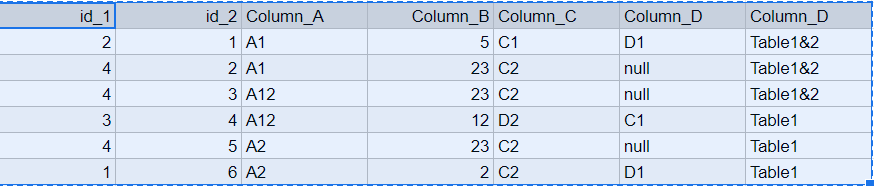
Expected Output:
CodePudding user response:
Another solution (I am working in Mariadb and don't have the dense_rank function - you can add that):
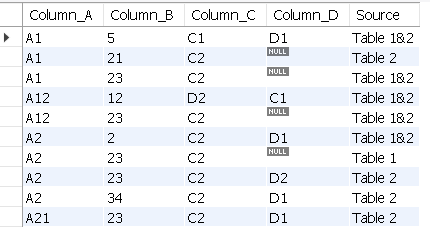
EDITED to make the Source more exactly what the OP requested:
SELECT Column_A,
Column_B,
Column_C,
Column_D,
CONCAT("Table ",GROUP_CONCAT(TNAME1,TNAME2 ORDER BY TNAME2 SEPARATOR "&" )) AS Source
FROM
(SELECT Column_A,
Column_B,
Column_C,
Column_D,
"1" AS TNAME1,
"" AS TNAME2
FROM table_name1
UNION
SELECT Column_A,
Column_B,
Column_C,
Column_D,
"" AS TNAME1,
"2" AS TNAME2
FROM table_name2
) AS SQL1
GROUP BY Column_A,Column_B,Column_C,Column_D;
CodePudding user response:
Would something like this work for you if @lemon's solution doesn't?
with cteConsolidate as (
select 'Table 1' as tabname, * from #table_name1
union
select 'Table 2' as tabname, * from #table_name2
)
select column_a, column_b, column_c, column_d, case when count(*) = 1 then min(tabname) else 'Both' end
from cteConsolidate
group by column_a, column_b, column_c, column_d
CodePudding user response:
If EXCEPT and INTERSECT are operators available for your DBMS, like in PostgreSQL and MySQL, you can apply a union over the three separate sets:
- records appearing in table1 but not in table2
- records appearing in table2 but not in table1
- records appearing in both tables
SELECT *, 'tab1' AS orig FROM table1 EXCEPT SELECT * FROM table2
UNION ALL
SELECT *, 'tab2' AS orig FROM table2 EXCEPT SELECT * FROM table1
UNION ALL
SELECT *, 'both' AS orig FROM table1 INTERSECT SELECT * FROM table2