I have a Dataframe as follows and would like to remove duplicates with respect to three columns: user, url and timestamp (only if it is less than or equal <= 10 sec of last occurrence). Here I elaborate rows with # comment:
timestamp user url
0 2018-02-07 00:00:00 02:00 ip0 google.com # 1st occurrence
1 2018-02-07 00:00:02 02:00 ip1 xe.com # 1st occurrence
2 2018-02-07 00:00:10 02:00 ip7 facebook.com
3 2018-02-07 00:00:11 02:00 ip1 xe.com # duplicate <= 10 sec : drop
4 2018-02-07 00:00:13 02:00 ip1 xe.com # not a duplicate, comparing with 1st occurrence : leave it
5 2018-02-07 00:00:15 02:00 ip2 example.com
6 2018-02-07 00:00:20 02:00 ip3 ebay.com
7 2018-02-07 00:00:55 02:00 ip1 xe.com # not a duplicate: leave it
8 2018-02-07 00:00:59 02:00 ip5 amazon.com
9 2018-02-07 00:01:02 02:00 ip1 xe.com # duplicate <= 10 sec : drop
10 2018-02-07 00:01:28 02:00 ip0 google.com # not a duplicate: leave it
I tried df = df.drop_duplicates(subset=['user', 'url'], keep='first') which removes all possible duplicate regardless of timestamp.
My expected results should look something like this:
timestamp user url
0 2018-02-07 00:00:00 02:00 ip0 google.com
1 2018-02-07 00:00:02 02:00 ip1 xe.com
2 2018-02-07 00:00:10 02:00 ip7 facebook.com
4 2018-02-07 00:00:13 02:00 ip1 xe.com
5 2018-02-07 00:00:15 02:00 ip2 example.com
6 2018-02-07 00:00:20 02:00 ip3 ebay.com
7 2018-02-07 00:00:55 02:00 ip1 xe.com
8 2018-02-07 00:00:59 02:00 ip5 amazon.com
10 2018-02-07 00:01:28 02:00 ip0 google.com
What is most compact and easiest way to create some sort of mask (if that is a practical idea) to exclude rows which fall within certain threshold, e.g., 10 seconds, of the fist occurrence?
Cheers,
CodePudding user response:
Here is a solution that works for your original question, but doesn't work for the new logic of "overlapping" time-windows where event1 and event2 occur within 10 seconds, and so do event2 and event3. This code is only keeping event1 in this scenario, but I see you want event1 and event3 in the update. I don't know how to get the new "overlapping" behavior without a slow loop
Solution below uses groupby and shift to identify the previous event by each user/url group, and then filters by timedelta. I think this solution is fast and scales well
import pandas as pd
import io #just for reading in the example table
import datetime
df = pd.read_csv(io.StringIO("""
day timestamp user url
0 2018-02-07 00:00:00 02:00 ip0 google.com
1 2018-02-07 00:00:02 02:00 ip1 xe.com
2 2018-02-07 00:00:10 02:00 ip7 facebook.com
3 2018-02-07 00:00:11 02:00 ip1 xe.com
4 2018-02-07 00:00:13 02:00 ip1 xe.com
5 2018-02-07 00:00:15 02:00 ip2 example.com
6 2018-02-07 00:00:20 02:00 ip3 ebay.com
7 2018-02-07 00:00:55 02:00 ip1 xe.com
8 2018-02-07 00:00:59 02:00 ip5 amazon.com
9 2018-02-07 00:01:02 02:00 ip1 xe.com
10 2018-02-07 00:01:28 02:00 ip0 google.com
"""),delim_whitespace=True)
df['timestamp'] = pd.to_datetime(df['day'] ' ' df['timestamp']) #get timestamp column as datetime
#Make a new column of the previous times, by user/url, for each row
df['prev_time'] = df.groupby(['url','user'])['timestamp'].shift()
#keep rows which either don't have a previous time (null), or are more than 10 seconds timedelta from prev
threshold = datetime.timedelta(0,10) #0 days, 10 seconds
filt_df = df[df['prev_time'].isnull() | df['timestamp'].sub(df['prev_time']).gt(threshold)]
print(filt_df)
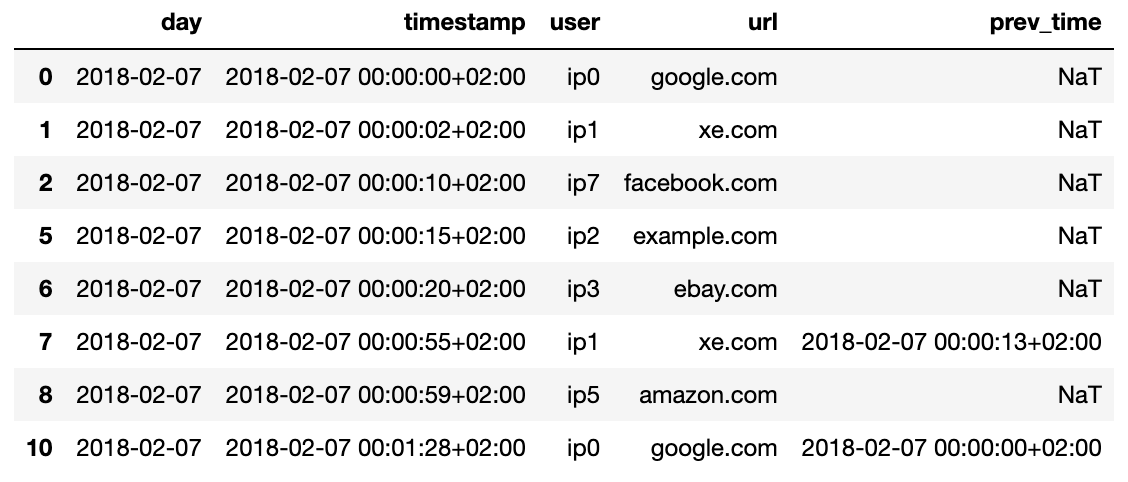
Here's the output filt_df table
CodePudding user response:
I would make an additional column from the timestamp column - seconds, and then do something like the following:
df = pd.concat([df[df['seconds']<=10].drop_duplicates(subset=['timestamp', 'user', 'url'], keep='first'), df[df['seconds']>10]])
But I think there is a more compact and convenient way.