I have a pandas dataframe, lets call it df1 that looks like this (the follow is just a sample to give an idea of the dataframe):
| Ac | Tp | Id | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|
| Efecty | FC | IQ_EF | 100 | 200 | 45 |
| Asset | FC | 52 | 48 | 15 | |
| Debt | P&G | IQ_DEBT | 45 | 58 | 15 |
| Tax | Other | 48 | 45 | 78 |
And I want to fill the blank spaces using a in the 'Id' column using the next auxiliar dataframe, lets call it df2 (again, this is just a sample):
| Ac | Tp | Id |
|---|---|---|
| Efecty | FC | IQ_EF |
| Asset | FC | IQ_AST |
| Debt | P&G | IQ_DEBT |
| Tax | Other | IQ_TAX |
| Income | BAL | IQ_INC |
| Invest | FC | IQ_INV |
To get df1 dataframe, looking like this:
| Ac | Tp | Id | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|
| Efecty | FC | IQ_EF | 100 | 200 | 45 |
| Asset | FC | IQ_AST | 52 | 48 | 15 |
| Debt | P&G | IQ_DEBT | 45 | 58 | 15 |
| Tax | Other | IQ_TAX | 48 | 45 | 78 |
I tried with this line of code but it did not work:
df1['Id'] = df1['Id'].mask(df1('nan')).fillna(df1['Ac'].map(df2('Ac')['Id']))
Can you guys help me?
CodePudding user response:
Merge the two frames on Ac and Tp columns and assign the Id column from this result to df1.Id. This works similar to Excel Vlookup functionality.
ac_tp = ['Ac', 'Tp']
df1['Id'] = df1[ac_tp].merge(df2[[*ac_tp, 'Id']])['Id']
CodePudding user response:
In a similar vein you could also try:
df['Id'] = (df.merge(df2, on = ['Ac', 'Tp'])
.pipe(lambda d: d['Id_x'].mask(d['Id_x'].isnull(), d['Id_y'])))
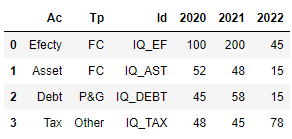
Ac Tp Id 2020 2021 2022
0 Efecty FC IQ_EF 100 200 45
1 Asset FC IQ_AST 52 48 15
2 Debt P&G IQ_DEBT 45 58 15
3 Tax Other IQ_TAX 48 45 78