I have an Arabic name and I am trying to split the Arabic characters and at the same time to identify the character if First, Middle or Last Here's my try but I couldn't fix the code
Sub Split_Arabic_Name()
Dim sName As String, i As Long
sName = "حاتم علاء خميس سيد"
Dim result() As String
Dim index As Integer
index = 0
For i = 1 To Len(sName)
If AscW(Mid(sName, i, 1)) >= &HD800 And AscW(Mid(sName, i, 1)) <= &HDBFF Then
ReDim Preserve result(index)
result(index) = Mid(sName, i, 2)
index = index 1
i = i 1
Else
If Mid(sName, i, 1) <> " " Then
ReDim Preserve result(index)
result(index) = Mid(sName, i, 1)
index = index 1
End If
End If
Next i
Dim arrName() As String
ReDim arrName(0 To UBound(result), 0 To 1)
Dim first As Integer, middle As Integer, last As Integer
first = 0
middle = 0
last = 0
For i = 0 To UBound(result)
arrName(i, 0) = result(i)
If (i = 0) Or (Mid(sName, i 1, 1) = " ") Then
arrName(i, 1) = "First"
ElseIf Mid(sName, i 1, 1) = " " Then
arrName(i, 1) = "Last"
Else
arrName(i, 1) = "Middle"
End If
Next i
Range("H1").Resize(UBound(arrName, 1) 1, UBound(arrName, 2) 1).Value = arrName
End Sub
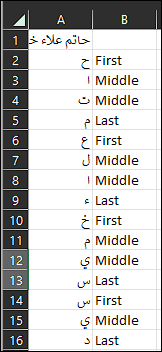
The spaces are considered as marks. While the name starts with ح so this is [First] -- then ا then ت [these are Middle] --- then م followed be space so this is [Last]
the second name after space which is ع , should be [First] -- then the characters ل then ا [Middle] --- and the character ء [Last] as it is before the space .. and so on
as for the last name سيد , the [First] is س but ي [Middle] --and the last character in the whole name not followed be space but it is the last character so it is [Last]
This is a snapshot of the results I got and I typed the remarks

CodePudding user response:
As per my comment, a regular expression might not be a bad idea here:
Sub Test()
Dim s As String: s = [A1]
Dim x As Long: x = 1
Dim tst As String
With CreateObject("vbscript.regexp")
.Global = True
.Pattern = "(?:^|\s)(\S)|(\S)(?!\s|$)|(\S)(?=\s|$)"
Set matches = .Execute(s)
If Not matches Is Nothing Then
For Each Match In matches
x = x 1
tst = Match.Submatches(0) & Match.Submatches(1) & Match.Submatches(2)
Select Case tst
Case Match.Submatches(0)
Cells(x, 2).Value = "First"
Case Match.Submatches(1)
Cells(x, 2).Value = "Middle"
Case Match.Submatches(2)
Cells(x, 2).Value = "Last"
End Select
Cells(x, 1).Value = tst
Next
End If
End With
End Sub
The idea behind the pattern (?:^|\s)(\S)|(\S)(?!\s|$)|(\S)(?=\s|$) is to catch every character other than whitespace as a seperate match in their own respective group. The regex engine does recognize that it needs to read the input right to left. To break this pattern down:
(?:^|\s)(\S)- A single non-whitespace character that is preceded by the start of the input or a whitespace character;(\S)(?!\s|$)- A non-whitespace character not followed by a whitespace character nor the end-line. This does catch the correct characters apart from the first character because of the order or the alternations in the pattern;(\S)(?=\s|$)- A non-whitespace character that is followed by a whitespace character nor the end-line. This does catch the correct characters apart from the first character because of the order or the alternations in the pattern.
So each match in group 1 is a 'First', each match in group 2 is 'Middle' and each match in group 3 is 'Last'.
See an online demo