introduction
Now there are lots of books introduce how to create a search engine, I in the bookstore has hand over some, but mostly books is too thick, too many words, have a kind of waste of life feeling, introduction to remember it took me the book which was written by Yan Hongfei "search engine", through this book, I have accumulated about the basic knowledge of search engine, then the paper combined with the foreigner, finally completed his master's thesis, "search engine" this book mainly elaborated the search engine's core concepts and ideas, while in the concrete to practice point; I was in a website has accumulated some practical experience, so want to contribute a little more aware, I hope if can impact on the people in need a little help, it is enough,
A search engine can do the most fundamental thing is to accept a query input, and then gives some results associated with the query input, our common search engine baidu is such a typical example, baidu has occupied most of the domestic share of the search, then newcomers to hope in existing search market share, to create the concept of vertical search, vertical search is relative to a general search engines such as baidu or Google, and that this type of search engines often only in one area, such as domestic now commonly used to search the bt and thunderbolt resources search engine, but this kind of search engine only limits the general scope of the search query, essence and the universal search engine is no different, in the concrete practice, it is more simple,
I personally like to division, from the aspects of application scope of the search engine can be divided into ordinary Internet search engine and web site search engine, the Internet search engines need to face the bad data environment, it is collect the web page information from various sites, and these website HTML code can be extremely is not standard, the search engine from the non-standard code to be able to find out useful information, compared to the Internet search engine, site search engine is much easier, it only treatment station within limited text messages, and for the website builder, can limit the content of the need to be search, most of the time, site search engine doesn't need to deal with web page code can direct access to the information itself,
In subsequent a series of articles about how to create a search engine, I'll introduce you to implement a general search engine required basic knowledge, and help to build a simple Internet search engines and site search engine, but in all this before you begin, readers need to know the basic knowledge of programming and knowledge of linear algebra, otherwise Yan Hongfei teacher "search engine" is enough, I will try to use pseudo code in the article, as far as possible the reference knowledge of linear algebra, but I still suggest the reader to learn c language and javascript, we will also involve in the specific practice nodejs and mongo, although the two is not a programming language, but quite useful tool of middleware, have time, you also want to know, if you ever learn Java, nodejs is equivalent to weblogic, and directing is an oracle database,
CodePudding user response:
Search engine, the basic framework ofA complete network of general search engine on the logic is made up of four parts, according to the figure 1, divided into data acquisition, data processing, data index, data services,
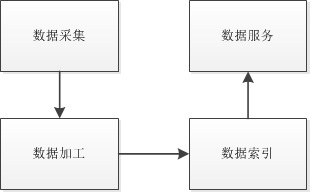
Figure 1
Data acquisition module is commonly known as a spider web crawler or network, although the name is very image, but from the point of view of practice, the process of a computer program and the spontaneous behavior of insects have very big difference, need to be able to get correct data acquisition module to the web pages of the site, its behavior is more like a constant after we enter the url in your browser, click on the link, so more apt to say that the data acquisition module is simulated by a web browser, and simulates the human web click behavior, extensive land, data acquisition module should have two basic functions:
1: according to the web address (URL) to get the corresponding web page file,
2: analyze the web page in the file link address and effective information text,
Data processing module is the core of the search engine function, it is responsible for the data acquisition module to collect useful information of web pages text processing, make we humans can read text messages can be in accordance with the rules set by computer to understand, for a primary search engine, the need to disassemble the text text, classified, if is Chinese, also need to disassemble for Chinese word segmentation, then parses the results sent to index module, index module further processed into the search engine's database, if you want to achieve a more intelligent advanced search engine, on the basis of the above steps, you'll also have to be able to realize the semantic understanding, so that when the user searches for "tomorrow week", search engines should be given contains "tomorrow is Saturday" or "tomorrow is Monday,,,,,,,, such as a result, not just with" tomorrow week "page of the five keywords result sets,
Data index module is another core of search engine, its relationship with the data processing module is like the human heart and lungs, be short of one cannot, the module of main function is to save data processing module of processing results in a standard data structure, the aim is to provide convenience for the next data service module, data service module can be finished in a very short time on the Internet information retrieval of data,
Data service module is to provide service search engine external interface, it can carry on the timely response to external input, and associated data index module, remove the users find the content of the web page as a result, most of the time, in order to be able to efficiently to feedback of user behavior, search engines often in this module implement some forecast or caching algorithm, don't encourage every query of the user to implement a complete data search process,
Can be seen from the above description of the four modules, search engine and a library of books retrieval system is not much difference, and the module of search engine chain is one-way and unique, there is no need for data interaction between multiple modules, or data interaction is a two-way street, only this point, the search engine on the logic is relatively simple, and I believe that readers as long as can stick to, finally achieve a practical application of search engine is completely no problem,
CodePudding user response:
Vertical search and on-site searchCompared with general Internet search engines, the so-called vertical search engines and site search engines are more simple in concept, can think of them as in the existing concept of general search engine on the cutting of the products, after vertical search is to search for a particular industry field, such as BT resources search search engines, general this class is to simplify the search engines on the data acquisition end, just get a designated site of web resources, and the data processing end, BT resources search engine, for example, the engine only from the web information resources can be derived from the name with the keyword torrent links, and ignore other information, the data index module, do simple keyword indexing engine, don't need to semantic processing, such as on-site search engine is more simple, the engine in the data acquisition module merely passively waiting for the information input, this is because the design of the site can be controlled, in any of the information is recorded on site and send a copy to the search engine, search engine can perform its subsequent logical process, search BBS posts is a typical case, when a user submits a post, the site put forward submissions to on-site search engine, search engine after receiving post text, processing of data and index put in storage, this all don't need to page file processing, avoid a lot of tabs to filter work,
As more and more web applications use javascript to dynamically generate user content, the traditional general Internet search engine is losing its traditional advantage, under the design concept of mobile first, traditional general search engines to collect the static web page content effectively may contain only one line keyword code, but the web pages in the client can show a rich and colorful content, so in the near future, on-site search will play a greater role, may every public site will have a personalized search engine, originally provided by the general search engine site search will gradually disappear,
CodePudding user response:
Wood down oh · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·CodePudding user response:
I said, will updateCodePudding user response:
O brother, updateCodePudding user response:

CodePudding user response:
I can say, search engine has now entered the stage of artificial intelligence? Now more important is how to show, instead of how to word segmentation, how to index and so on, these technology are mature and stable,