I have a .csv file that looks partly like this in form of a table:

Each row represtents an entity in this case games. Collumn "0" are links to their dbpedia page, collumn "1" represents labels and collumn "2" is an index. It starts at 1 and counts up.
What I'd like in the end is a list of just the links e.g. collumn "1" but sorted by collumn "2".
I've done it the same way for alot of other tables but for this one it seems the method breaks and I don't know why.
import pandas as pd
entities = pd.read_csv("24142265_0_4577466141408796359.csv", header=None)
entitiesUri = [str(ent) for ent in entities[0]]
tmp = entitiesUri.copy()
#I sort 'entitiesUri' by the seconde collumn in 'entities' and the index of the link in tmp
entitiesUri.sort(key = lambda k: int(entities[2][tmp.index(k)]))
I've created a copy of entitiesUri (tmp) to be sure that the sort() method doesn't mess up when using the list it has to sort in the lambda function.
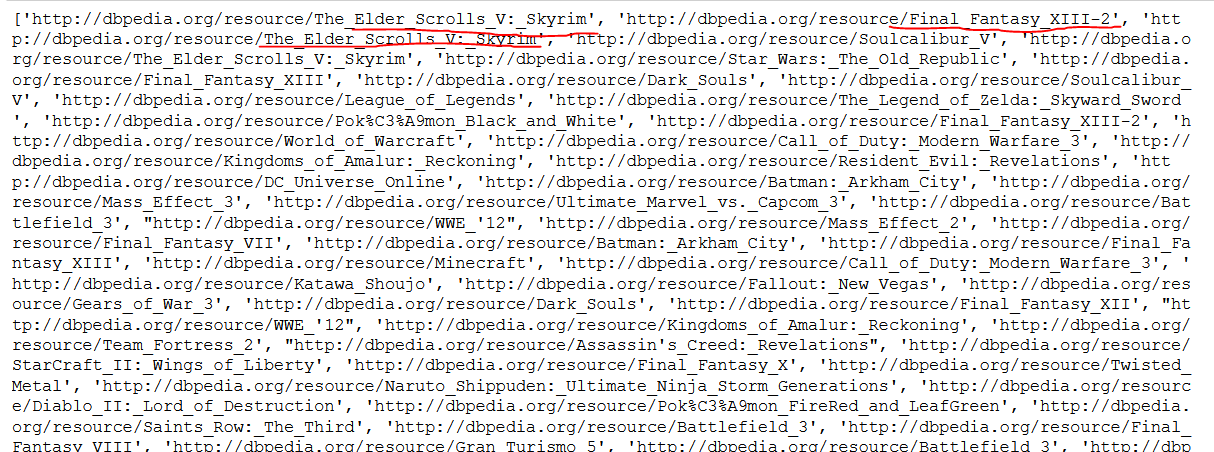
This is the print of "entitiesUri":

It didn't sort the links by the index but neither alphabetically it seems. But somehow it buchned the same games together in a random order?
I also used
entitiesUri = sorted(entitiesUri, key = lambda k: int(entities[2][tmp.index(k)]))
instead of sort() but the results are the same. The only thing that worked for me this far was the sort_values() function from Pandas
entities = entities.sort_values(2)
entitiesUri = [ent for ent in entities[0]]
With the right result:
but this methods slows me down alot. Any Ideas why sort() and sorted() breaks?
I've linked to dropbox where you can download the .csv file if you want to try it out yourself.
https://www.dropbox.com/s/ld8u4td5rk4vn71/24142265_0_4577466141408796359.csv?dl=0
CodePudding user response:
The reason why the first approach does not work as you would expect is that your input has duplicates in the URL column and that list.index() returns the index of the first item.
$ grep The_Elder_Scrolls_V 24142265_0_4577466141408796359.csv
"http://dbpedia.org/resource/The_Elder_Scrolls_V:_Skyrim","the elder scrolls v: skyrim","3"
"http://dbpedia.org/resource/The_Elder_Scrolls_V:_Skyrim","the elder scrolls v: skyrim","1"
"http://dbpedia.org/resource/The_Elder_Scrolls_V:_Skyrim","the elder scrolls v: skyrim","5"
So, for example, key = lambda k: int(entities[2][tmp.index(k)]) returns 3 (the value in the last column of the dataframe for the first occurrence of the URL above) for all 3 occurrences in the dataframe.
>>> for e in tmp:
... if e == 'http://dbpedia.org/resource/The_Elder_Scrolls_V:_Skyrim':
... print(e, int(entities[2][tmp.index(e)]))
...
http://dbpedia.org/resource/The_Elder_Scrolls_V:_Skyrim 3
http://dbpedia.org/resource/The_Elder_Scrolls_V:_Skyrim 3
http://dbpedia.org/resource/The_Elder_Scrolls_V:_Skyrim 3
As 3 is the smallest value (you can verify that by removing the if statement from the above listing), the URL appears first and 3 times in the output of sorted() and sort(). Removing the if statement will also make obvious why sorting entitiesUri produces the result you get.