I have a table with the time a given store opened during a couple of days, like you can see below (OPENING_HOUR is set as 24h time format, so all the hours on the table are AM).
>>> BUSINESS_HOURS
DATE | STORE_ID | OPENING_HOUR
________________________________________
0 2021-06-01 | 222 | 11
1 2021-06-02 | 222 | 11
2 2021-06-03 | 222 | 11
3 2021-06-04 | 222 | 11
4 2021-06-05 | 222 | 11
5 2021-06-06 | 222 | 11
6 2021-06-07 | 222 | 12
7 2021-06-08 | 222 | 11
8 2021-06-09 | 222 | 11
9 2021-06-10 | 222 | 12
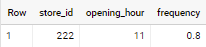
Now I need to group the data by id and tell which opening_hour was most frequent. In the case bellow, 11am was present in 80% of the cases, so I need something like this:
>>> DATA_GROUPED
STORE_ID | OPENING_HOUR | FREQUENCY
________________________________________
0 222 | 11 | 0.8
Is that possible using only SQL? Thank you for your help, guys!
CodePudding user response:
You can use window functions:
select store_id, opening_hour, count(*) as cnt,
count(*) * 1.0 / sum(count(*)) over () as ratio
from t
where store_id = 1
group by store_id, opening_hour
order by cnt desc
limit 1;
If you want this for all stores, you can use window functions:
select t.* except (seqnum)
from (select store_id, opening_hour, count(*) as cnt,
count(*) * 1.0 / sum(count(*)) over () as ratio,
row_number() over (partition by store_id order by count(*) desc) as seqnum
from t
group by store_id, opening_hour
) t
where seqnum = 1;
CodePudding user response:
I found an way by using window functions and CTEs.
WITH Q1 AS (
SELECT
DISTINCT STORE_ID,
OPENING_HOUR,
COUNT(OPENING_HOUR) AMOUNT,
ROW_NUMBER() OVER(PARTITION BY STORE_IDORDER BY COUNT(OPENING_HOUR) DESC) as RANK
FROM T1
GROUP BY 1, 2
)
SELECT
STORE_ID,
OPENING_HOUR,
ROUND((AMOUNT/SUM(AMOUNT) OVER(PARTITION BY STORE_ID)),2) AS SHARE
FROM Q1-- WHERE RANK = 1
Not the shortest answer out there but it works fine!
CodePudding user response:
With windowing function, this one solution:
WITH business_hours as (
SELECT DATE("2021-06-01") as date, 222 as store_id, 11 as opening_hour
UNION ALL
SELECT "2021-06-02", 222, 11
UNION ALL
SELECT "2021-06-03", 222, 11
UNION ALL
SELECT "2021-06-04", 222, 11
UNION ALL
SELECT "2021-06-05", 222, 11
UNION ALL
SELECT "2021-06-06", 222, 11
UNION ALL
SELECT "2021-06-07", 222, 12
UNION ALL
SELECT "2021-06-08", 222, 11
UNION ALL
SELECT "2021-06-09", 222, 11
UNION ALL
SELECT "2021-06-10", 222, 12)
, agg as (SELECT DISTINCT store_id, opening_hour,
COUNT(store_id) OVER (partition by opening_hour, EXTRACT(MONTH FROM date)) as total_open_per_hour,
COUNT(store_id) OVER (partition by EXTRACT(MONTH FROM date)) as total_open,
from business_hours)
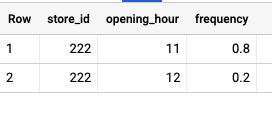
SELECT store_id, opening_hour, safe_divide(total_open_per_hour, total_open) frequency FROM agg
Result:
CodePudding user response:
Consider below approach
select * from (
select distinct store_id, opening_hour,
count(1) over(partition by opening_hour) / count(1) over() frequency
from business_hours
)
where true
qualify row_number() over(partition by store_id order by frequency desc) = 1
gives you the most frequent opening_hour per store
If applied to sample data in your question - output is