Situation
I'm trying to get the word Non-Compliant in 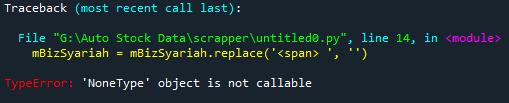
Question
How can I remove the span tag to get the text out of this tag?
Thanks!
CodePudding user response:
Dealing with beautifulsoup the easiest way to grab the text of a tag is .text or if you want to grab and modify (join and strip) get_text().
mBizSyariah.text #contains whitespaces
mBizSyariah.get_text(strip=True) #without additional whitespaces
Example
import requests
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36 '
}
mBizLink = requests.get(str('https://www.malaysiastock.biz/Corporate-Infomation.aspx?securityCode=7164'), headers=header)
mBizParser = BeautifulSoup(mBizLink.text, 'html.parser')
mBizParser.find('label', {'id' : 'ctl17_lbShariah'}).find('span').get_text(strip=True)
Output:
'Non-Compliant'