I have a dataset like below
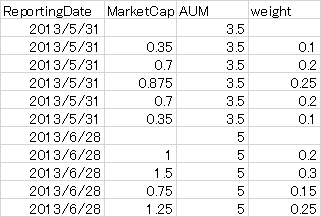
data = {'ReportingDate':['2013/5/31','2013/5/31','2013/5/31','2013/5/31','2013/5/31','2013/5/31',
'2013/6/28','2013/6/28',
'2013/6/28','2013/6/28','2013/6/28'],
'MarketCap':[' ',0.35,0.7,0.875,0.7,0.35,' ',1,1.5,0.75,1.25],
'AUM':[3.5,3.5,3.5,3.5,3.5,3.5,5,5,5,5,5],
'weight':[' ',0.1,0.2,0.25,0.2,0.1,' ',0.2,0.3,0.15,0.25]}
# Create DataFrame
df = pd.DataFrame(data)
df.set_index('Reporting Date',inplace=True)
df
Just a sample of a 8000 rows dataset.
ReportingDate starts from 2013/5/31 to 2015/10/30. It includes data of all the months during the above period. But Only the last day of each month. The first line of each month has two missing data. I know that
- the sum of weight for each month is equal to 1
- weight*AUM is equal to MarketCap
I can use the below line to get the answer I want, for only one month
a= (1-df["2013-5"].iloc[1:]['weight'].sum())
b= a* AUM
df.iloc[1,0]=b
df.iloc[1,2]=a
How can I use a loop to get the data for the whole period? Thanks
CodePudding user response:
One way using pandas.DataFrame.groupby:
# If whitespaces are indeed whitespaces, not nan
df = df.replace("\s ", np.nan, regex=True)
# If not already datatime series
df.index = pd.to_datetime(df.index)
s = df["weight"].fillna(1) - df.groupby(df.index.date)["weight"].transform(sum)
df["weight"] = df["weight"].fillna(s)
df["MarketCap"] = df["MarketCap"].fillna(s * df["AUM"])
Note: This assumes that dates are always only the last day so that it is equivalent to grouping by year-month. If not so, try:
s = df["weight"].fillna(1) - df.groupby(df.index.strftime("%Y%m"))["weight"].transform(sum)
Output:
MarketCap AUM weight
ReportingDate
2013-05-31 0.350 3.5 0.10
2013-05-31 0.525 3.5 0.15
2013-05-31 0.700 3.5 0.20
2013-05-31 0.875 3.5 0.25
2013-05-31 0.700 3.5 0.20
2013-05-31 0.350 3.5 0.10
2013-06-28 0.500 5.0 0.10
2013-06-28 1.000 5.0 0.20
2013-06-28 1.500 5.0 0.30
2013-06-28 0.750 5.0 0.15
2013-06-28 1.250 5.0 0.25