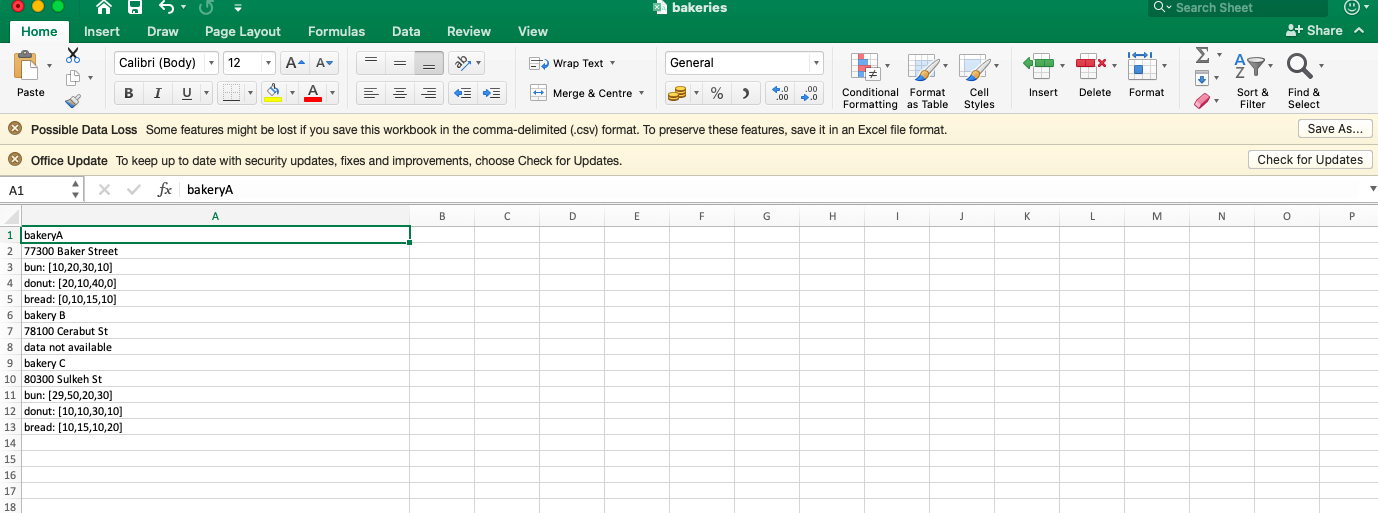
This data was earlier provided as a .txt file. I converted it to .csv format and tried to sort it into the wanted form, but failed. I am trying to find ways to convert this data structure (as displayed below):
bakeryA
77300 Baker Street
bun: [10,20,30,10]
donut: [20,10,40,0]
bread: [0,10,15,10]
bakery B
78100 Cerabut St
data not available
bakery C
80300 Sulkeh St
bun: [29,50,20,30]
donut: [10,10,30,10]
bread: [10,15,10,20]
into this data frame:
| Name | Address | type | salt | sugar | water | flour |
|---|---|---|---|---|---|---|
| Bakery A | 77300 Baker Street | bun | 10 | 20 | 30 | 10 |
| Bakery A | 77300 Baker Street | donut | 20 | 10 | 40 | 0 |
| Bakery A | 77300 Baker Street | bread | 0 | 10 | 15 | 10 |
| Bakery B | 78100 Cerabut St | Nan | Nan | Nan | Nan | Nan |
| Bakery C | 80300 Sulkeh St | bun | 29 | 50 | 20 | 30 |
| Bakery C | 80300 Sulkeh St | donut | 10 | 10 | 30 | 10 |
| Bakery C | 80300 Sulkeh St | bread | 10 | 15 | 10 | 20 |
Thank you!
CodePudding user response:
This has very little to do with pandas and more with parsing non-structured source into structured data. Try this:
from ast import literal_eval
from enum import IntEnum
class LineType(IntEnum):
BakeryName = 1
Address = 2
Ingredients = 3
data = []
with open('data.txt') as fp:
line_type = LineType.BakeryName
for line in fp:
line = line.strip()
if line_type == LineType.BakeryName:
name = line # the current line contains the Bakery Name
line_type = LineType.Address # the next line is the Bakery Address
elif line_type == LineType.Address:
address = line # the current line contains the Bakery Address
line_type = LineType.Ingredients # the next line contains the Ingredients
elif line_type == LineType.Ingredients and line == 'data not available':
data.append({
'Name': name,
'Address': address
}) # no Ingredients info available
line_type = LineType.BakeryName # next line is Bakery Name
elif line_type == LineType.Ingredients:
# if the line does not follow the ingredient's format, we
# overstepped into the Bakery Name line. Then the next line
# is Bakery Address
try:
bakery_type, ingredients = line.split(':')
ingredients = literal_eval(ingredients.strip())
data.append({
'Name': name,
'Address': address,
'type': bakery_type,
'salt': ingredients[0],
'sugar': ingredients[1],
'water': ingredients[2],
'flour': ingredients[3],
})
except:
name = line
line_type = LineType.Address
df = pd.DataFrame(data)
This assume that your data file is in the format shown. A slight deviation (blank lines, for example) will throw it off.