I am trying to scrape yahoo finance website using BeautifulSoup and requests but not getting the correct soup. Its giving me a 404 page not found html code instead of giving me the original html code for the website . Here is my code.
from bs4 import BeautifulSoup
import requests
soup = BeautifulSoup(requests.get('https://finance.yahoo.com/quote/FBRX/profile?p=FBRX').text, 'lxml')
print(soup)
Here is my output:
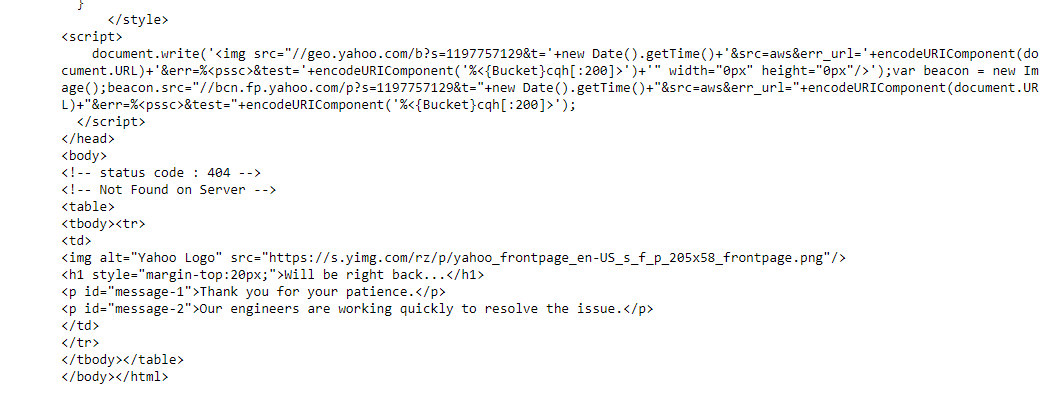
Can you help me in scraping this website.
CodePudding user response:
Try to set User-Agent HTTP header to obtain correct response from the server:
import requests
from bs4 import BeautifulSoup
url = "https://finance.yahoo.com/quote/FBRX/profile?p=FBRX"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:92.0) Gecko/20100101 Firefox/92.0"
}
soup = BeautifulSoup(requests.get(url, headers=headers).content, "html.parser")
print(soup.h1.text)
Prints:
Forte Biosciences, Inc. (FBRX)