I have below like dataframe where I have japanese,chinese languages in company name...
data = [['company1', '<U 042E><U 043F><U 0438><U 0442><U 0435><U 0440>'], ['company2',
'<c1>lom<e9>kszer Kft.'], ['company3', 'Ernst and young'],
['company4', '<c5>bo Akademi']]
df = pd.DataFrame(data, columns = ['Name', 'company_name'])
it looks like below
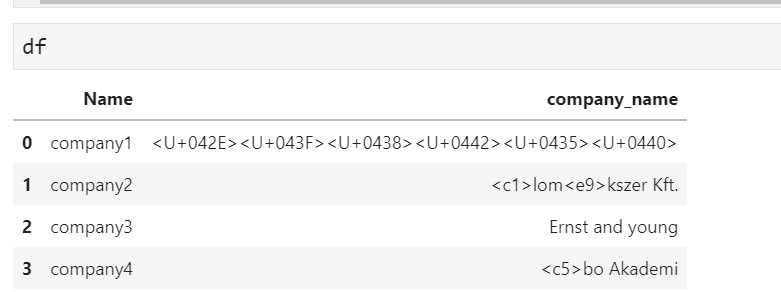
now all I want is to convert and translate these values to readable english values.
can I do that? , if yes, how , Please..
CodePudding user response:
Your examples do not exhibit a single unified encoding. We can speculate that the two-digit ones are Latin-1, but I'm guessing (based also on the duplicate question) that the truth is really more complex than that.
Anyway, for general direction at least, try this:
import re
...
for index in range(len(data)):
data[index][1] = re.sub(
r'<U\ ([0-9a-fA-F]{4})>',
lambda x: chr(int(x.group(1), 16)),
re.sub(
r'<([0-9a-fA-F]{2})>',
lambda x: chr(int(x.group(1), 16)),
data[index][1]))
Demo: https://ideone.com/X60x3Q
You can avoid the repeated lambda expression at the cost of a slightly more complex regular expression.
for index in range(len(data)):
data[index][1] = re.sub(
r'<(?:U\ )?((?<=\ )[0-9a-fA-F]{4}|(?<=<)[0-9a-fA-F]{2})>',
lambda x: chr(int(x.group(1), 16)),
data[index][1])
Demo: https://ideone.com/SkuvAJ
CodePudding user response:
This needs some work. I just translated it manually. Here it is:
>>> '<U 042E><U 043F><U 0438><U 0442><U 0435><U 0440>'
'<U 042E><U 043F><U 0438><U 0442><U 0435><U 0440>' # not useful!