Recently I was going through an SQL script as part of a task to check functionality of a data science process. I had a copy of a section of the script which had multiple sub queries and I refactored it to put the sub queries up the top in a with-clause. I usually think of this as an essentially syntactic refactoring operation that is semantically neutral. However, the operation of the script changed.
Investigation showed that it was due to the use of a row number over a partition in which the ordering within the partition was not complete. Changing the structure of the code changed something in the execution plan, that changed the order within the slack left by the incomplete ordering.
I made a note of this point and became less confident of this refactoring, although I hold the position that order should not affect the semantics, at least as long as it can be avoided.
My question is ...
other than assigning a row number, what operations have a value that is changed by the ordering?
CodePudding user response:
So are you saying to had gaps in the row_numbers()? or duplicate row_numbers? or just row numbers jumped around (unstable?)
Which functions are altered by incomplete/unstable order by functions, all the ones where you put OBER BY in the window function. Thus ROW_NUMBER or LAG or LEAD
But in general a sub-select and a CTE (with clause) are the same, the primary difference is multiple things can JOIN the same CTE (thus the Common part) this can be good/bad as you might save on some expensive calculation, but you might also slow down a critical path, and make the whole execution time slower.
Or the data might be a little more processed (due to JOIN's etc) and then the incomplete ODERBY/instability might be exposed.
CodePudding user response:
When windowed functions are involved, especially the ROW_NUMBER() the first thing to check is if the columns used for ordering produce a stable sort.
For instance:
CREATE TABLE t(id INT, grp VARCHAR(100), d DATE, val VARCHAR(100));
INSERT INTO t(id, grp, d, val)
VALUES (1, 'grpA', '2021-10-16', 'b')
,(2, 'grpA', '2021-10-16', 'a')
,(3, 'grpA', '2021-10-15', 'c')
,(4, 'grpA', '2021-10-14', 'd')
,(5, 'grpB', '2021-10-13', 'a')
,(6, 'grpB', '2021-10-13', 'g')
,(7, 'grpB', '2021-10-12', 'h');
-- the sort is not stable, d column has a tie
SELECT *
FROM (
SELECT t.*, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY d DESC) AS rn
FROM t) sub
WHERE sub.rn = 1 AND sub.val = 'a';
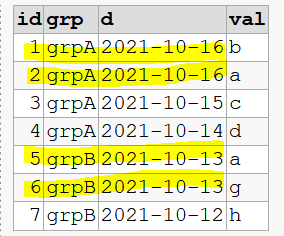
Depending of the order of operation it could return:
- 0 rows
- 1 row (id: 2)
- 1 row (id: 5)
- 2 rows(id: 2 and 5)
When query is refactored it could cause choosing a differnt path to access the data thus different result.
To check if sort is stable windowed COUNT could be used using all available columns:
SELECT *
FROM (
SELECT t.*, COUNT(*) OVER(PARTITION BY grp, d ) AS cnt
FROM t) sub
WHERE cnt > 1;