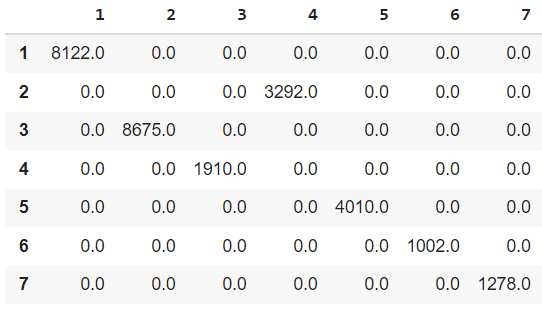
For the dataframe shown below, I want to do the following :
- In every row I want to determine the number of nonzero values, which I have been able to do using np.where.
- I then want to determine the column labels that contribute to these non-zero values in each row. Any help will be really appreciated. Thanks in advance
CodePudding user response:
To count your non-zeros in each row you can use nonzero_count from numpy package and perform the operation row-wise:
import numpy as np
df['non_zero_count'] = np.count_nonzero(df,axis=1)
>>> df
1 2 3 4 5 6 7 non_zero_count
0 8122 0 0 0 0 0 0 1
1 0 0 0 3292 0 1313 0 2
2 0 8675 0 0 0 0 0 1
3 0 0 1910 0 213 0 12312 3
4 0 0 0 0 4010 0 0 1
5 0 0 0 0 0 1002 0 1
6 0 0 0 0 0 0 1278 1
Then you can get the columns where a row contains a non-zero value with apply, so be cautious here if you have a big dataset at hand:
df['non_zero_label'] = df.drop('non_zero_count',axis=1)\
.apply(lambda r: r.index[r.ne(0)].to_list(), axis=1)
df
>>> df
1 2 3 4 5 6 7 non_zero_count non_zero_label
0 8122 0 0 0 0 0 0 1 [1]
1 0 0 0 3292 0 1313 0 2 [4, 6]
2 0 8675 0 0 0 0 0 1 [2]
3 0 0 1910 0 213 0 12312 3 [3, 5, 7]
4 0 0 0 0 4010 0 0 1 [5]
5 0 0 0 0 0 1002 0 1 [6]
6 0 0 0 0 0 0 1278 1 [7]
CodePudding user response:
Considering that the dataframe name is df:
df[df != 0].stack().reset_index(level=0, drop=True)
This returns a series with the column labels as index and the non-zero values, which for your example the output is:
1 8122.0
4 3292.0
2 8675.0
3 1910.0
5 4010.0
6 1002.0
7 1278.0
CodePudding user response:
You could do something like this:
df = pd.DataFrame({'x' : [ 0,0,9],'y' : [-1,3,0],'z' : [0,1.1,3]},index=['a','b','c'])
df["non_zero_columns"] = df.where(df == 0,
other=df.apply(lambda x: x.name),
axis=1).where(df != 0,
other="").apply(lambda row: ''.join(row.values), axis=1)
which gives:
x y z non_zero_columns non zero
a 0 -1 0.0 y 1
b 0 3 1.1 yz 2
c 9 0 3.0 xz 2
Apply that to your dataframe.
Another solution for the same dataframe would be:
cols = df.columns
df = df.apply(lambda x: x != 0)
df['Non_zero_columns'] = df.apply(lambda x: list(cols[x.values]), axis=1)
df['Length'] = df['Non_zero_columns'].str.len()
which produces:
x y z Non_zero_columns Length
a False True False [y] 1
b False True True [y, z] 2
c True False True [x, z] 2