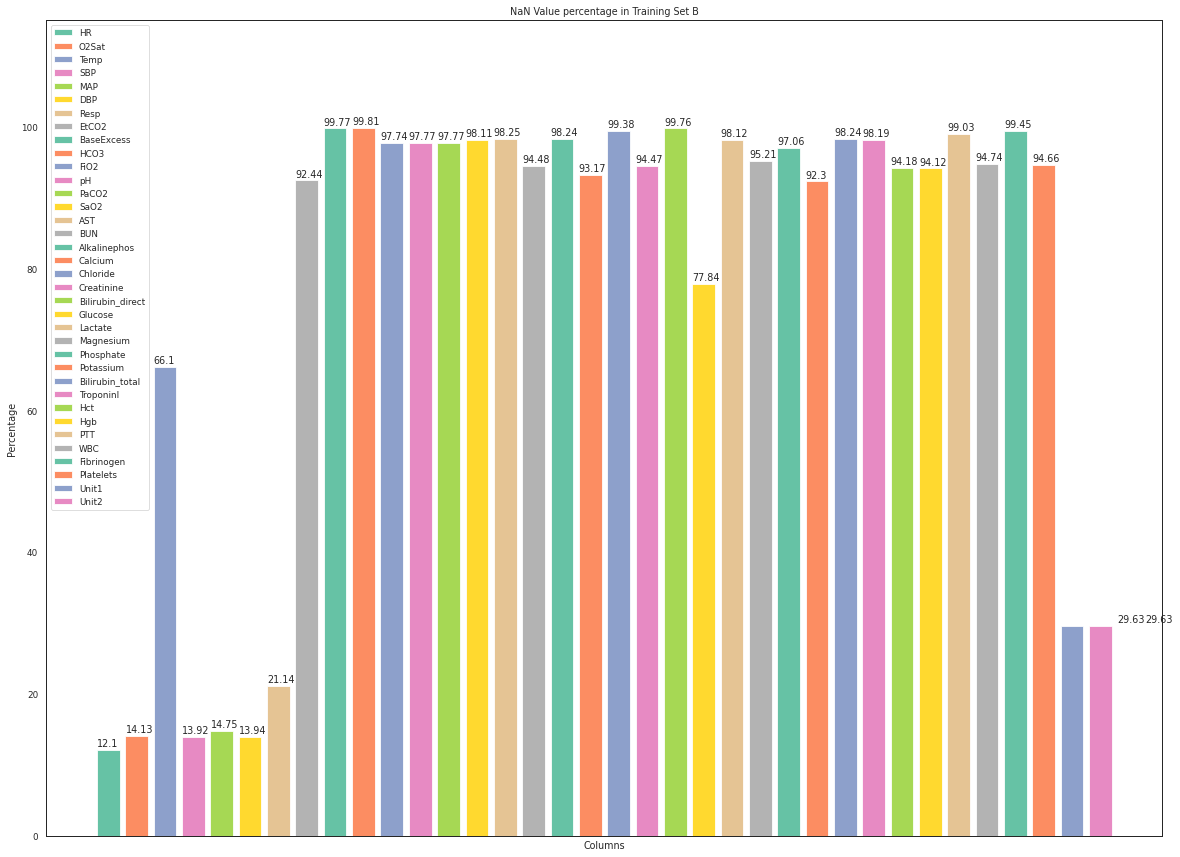
I calculated missing values in my dataframe using the code:
per_B = df.isna().mean().round(4) * 100
And plotted using the following code with NaN value count on top, but the last two value count position is misplaced.
f, ax = plt.subplots(figsize=(20, 15))
for i,item in enumerate(zip(per_B.keys(), per_B.values)):
if (item[1] > 0):
ax.bar(item[0], item[1], label = item[0])
ax.text(i - 0.40, item[1] 0.5 , str(np.round(item[1],2)))
ax.set_xticklabels([])
ax.set_xticks([])
plt.title('NaN Value percentage in Training Set B')
plt.ylim(0,115)
plt.ylabel('Percentage')
plt.xlabel('Columns')
plt.legend(loc='upper left')
plt.show()
Can someone help me with what went wrong in the code, as the last two column value counts are misplaced?
CodePudding user response:
The reason the text is misplaced, is that you let i increment even when you don't plot a bar (there seem to be two "items" with item[1] <= 0 just before the end). You could solve this by placing i outside the for and incrementing it only when a bar is drawn.
So, something like:
i = 0
for key, value in zip(per_B.keys(), per_B.values)):
if (value > 0):
ax.bar(key, value, label=key)
ax.text(i, value 0.5, str(np.round(value, 2)), ha='center')
i = i 1 # increment the counter
The code could be simplified using the