I have a code that does calculations with a DataFrame.
------------------------------------ ------------ ---------- ---- ------
| Name| Role|Experience|Born|Salary|
------------------------------------ ------------ ---------- ---- ------
| 瓮䇮滴ୗ┦附䬌┊ᇕ鈃디蠾综䛿ꩁ翨찘... | охранник| 16|1960|108111|
| 擲鱫뫉ܞ琱폤縭ᘵ훧귚۔♧䋐滜컑... | повар| 14|1977| 40934|
| 㑶뇨ꄳ壚ᗜ㙣샾ꎓ㌸翧쉟梒靻駌푤... | геодезист| 29|1997| 27335|
| ࣆ᠘䬆䨎⑁烸ᯠણ ᭯몇믊ຮ쭧닕㟣紕... | не охранн. | 4|1999 | 30000|
... ... ...
I tried to cache the table in different ways.
def processDataFrame(mode: String): Long = {
val t0 = System.currentTimeMillis
val topDf = df.filter(col("Salary").>(50000))
val cacheDf = mode match {
case "CACHE" => topDf.cache()
case "PERSIST" => topDf.persist()
case "CHECKPOINT" => topDf.checkpoint()
case "CHECKPOINT_NON_EAGER" => topDf.checkpoint(false)
case _ => topDf
}
val roleList = cacheDf.groupBy("Role")
.count()
.orderBy("Role")
.collect()
val bornList = cacheDf.groupBy("Born")
.count()
.orderBy(col("Born").desc)
.collect()
val t1 = System.currentTimeMillis()
t1-t0 // time result
}
I got results that made me think.
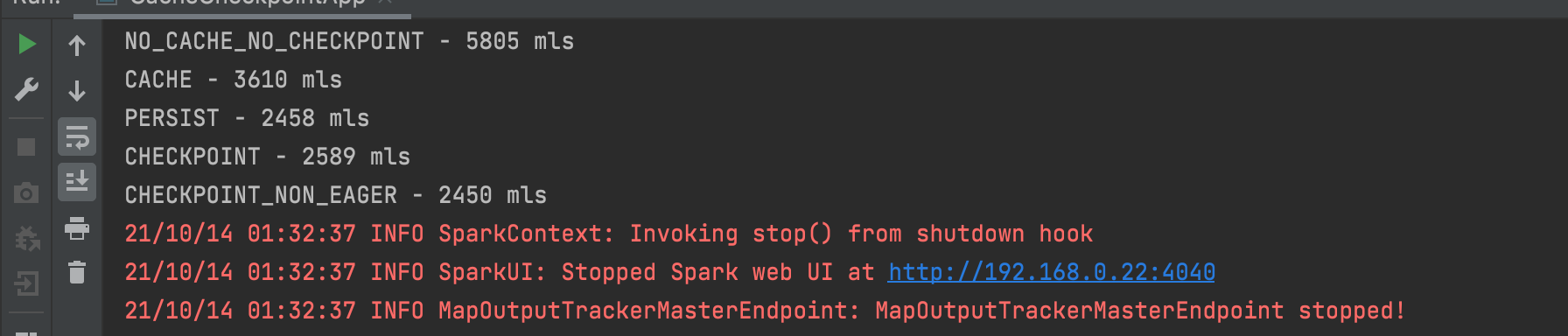
Why is checkpoint(false) more efficient than persist()? After all, a checkpoint needs time to serialize objects and write them to disk.
P.S. My small project on GitHub: https://github.com/MinorityMeaning/CacheCheckpoint
CodePudding user response:
I haven't checked your project but I think it's worth a minor discussion. I would prefer that you cleanly call out that you didn't run this code once but are averaging out several runs, to make a determination about performance on this specific dataset. (Not efficiency) Spark Clusters can have a lot noise that causes difference from job to job and averaging several runs really is required to determine performance. There are several performance factors (Data locality/Spark Executors, Resource contention, ect)
I don't think you can say "efficient" as these functions actually perform two different functionalities. They also will perform differently under different circumstance because of what they do. There are times you will want to check point, to truncate data lineage or after very computationally expensive operations. There are times when having the lineage to recompute is actually cheaper to do than writing & reading from disk.
The easy rule is, if you are going to use this table/DataFrame/DataSet multiple times cache it in memory.(Not Disk)
Once you hit an issue with a job that's not completing think about what can be tuned. From a code perspective/query perspective.
After that...
If and only if this is related to a failure of a complex job and you see executors failing, consider disk to persist the data. This should always be a later step in troubleshooting and never a first step in troubleshooting.
CodePudding user response:
Persist
Persisting or caching with StorageLevel.DISK_ONLY cause the generation of RDD to be computed and stored in a location such that subsequent use of that RDD will not go beyond that points in recomputing the linage. After persist is called, Spark still remembers the lineage of the RDD even though it doesn't call it. Secondly, after the application terminates, the cache is cleared or file destroyed
Checkpointing
Checkpointing stores the rdd physically to hdfs and destroys the lineage that created it. The checkpoint file won't be deleted even after the Spark application terminated. Checkpoint files can be used in subsequent job run or driver program Checkpointing an RDD causes double computation because the operation will first call a cache before doing the actual job of computing and writing to the checkpoint directory. You may want to read the article for more of the details or internals of Spark's checkpointing or Cache operations.
Persist(MEMORY_AND_DISK) will store the data frame to disk and memory temporary without breaking the lineage of the program i.e. df.rdd.toDebugString() would return the same output. It is recommended to use persist(*) on a calculation, that is going to be reused to avoid recalculation of intermediate results:
df = df.persist(StorageLevel.MEMORY_AND_DISK)
calculation1(df) calculation2(df)
Note, that caching the data frame does not guarantee, that it will remain in memory until you call it next time. Depending on the memory usage the cache can be discarded.
checkpoint(), on the other hand, breaks lineage and forces data frame to be stored on disk. Unlike usage of cache()/persist(), frequent check-pointing can slow down your program. Checkpoints are recommended to use when a) working in an unstable environment to allow fast recovery from failures b) storing intermediate states of calculation when new entries of the RDD are dependent on the previous entries i.e. to avoid recalculating a long dependency chain in case of failure