There is a dataframe df with 2 columns col1 and col2. Both columns have randomly spread 0s and 1s. More zeros than ones. If col1 has a 1 on an index, program should be able to look for next first 1 in col2 and get the difference of indices of both rows.
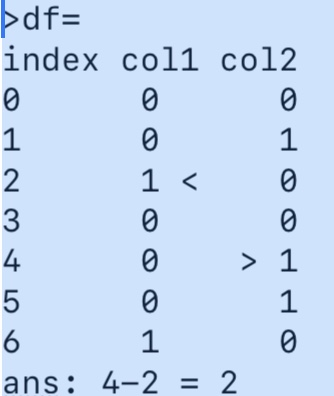
Everytime this distribution is different also the sequence length.
CodePudding user response:
Try with idxmax
id1 = df.col1.idxmax()
id2 = df.loc[id1:,'col2'].idxmax()
id2-id1
2
id2
4
id1
2
CodePudding user response:
I cannot see your posted image.
How about this.
import random
import pandas as pd
numrows = 10
df = pd.DataFrame({'c1': [random.randint(0, 1) for _ in range(numrows)], 'c2': [random.randint(0, 1) for _ in range(numrows)]})
print(df)
col1_index = None
for index, row in df.iterrows():
if col1_index is not None:
if row['c2'] == 1:
diff = col1_index - index
print(f'first occurrence of 1 at c2 is at index {index}, the index diff is {diff}')
col1_index = None
elif row['c1'] == 1:
col1_index = index
print(f'this index {index} has value 1 at c1')
Typical output
c1 c2
0 1 0
1 0 0
2 0 0
3 1 1
4 0 1
5 0 0
6 1 1
7 0 1
8 0 1
9 1 1
this index 0 has value 1 at c1
first occurrence of 1 at c2 is at index 3, the index diff is -3
this index 6 has value 1 at c1
first occurrence of 1 at c2 is at index 7, the index diff is -1
this index 9 has value 1 at c1