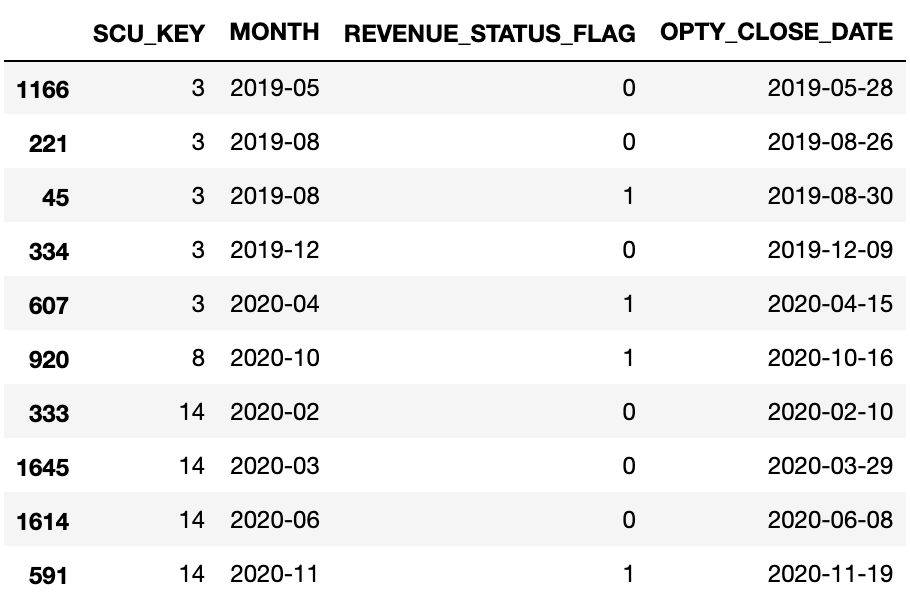
I am looking for a code that would get rid of rows for instances where the REVENUE_STATUS_FLAG is 0 before it becomes 1. HOWEVER, I would not like to get rid of the 0's after where 1 has occurred for that SCU_KEY (which is all based on sorted date). So with the image shown, the values I would like to get rid of these rows, which I categorized based on the index:
1166, 221 - (first two off SCU_KEY 3)
333, 1645, 1614 - (from SCU_KEY 14)
You will notice that I don't want to get rid of 334 from SCU_KEY 3 and that is because of the 1 occurring right before it from 45. This df is bigger than is shown so manually inputting the specific numbers mentioned does not suffice.
CodePudding user response:
Since you only care about the 0's before the 1's, you can use the cumulative sum function over the SCU_KEY to find the rows where it is the first non-zero or after the first non-zero. Cumulative sum becomes how many 1's were seen in this row or before this row. As long as that is 1 or more, you keep the row.
df = <your data frame>
df[df.groupby('SCU_KEY').cumsum().values >= 1]`