Currently finding the duplicates but the data is not showing the row number, name and number and isn't outputting correctly (See below for expected output).
Here are the sample files:

Current result
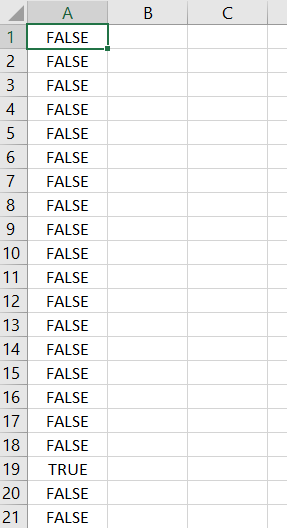
Currently Stuck code
import pandas as pd
import os
df_state=pd.read_csv(r'D:\NP Year 3\CNETF\Labs\Lab 2\A2c Python Exercises\2 Duplicated\names_dup2.csv', quoting=1, header=None)[0] \
.str.split('\t', expand=True) \
.duplicated() \
.to_csv('D:\\NP Year 3\\CNETF\\Labs\\Lab 2\\A2c Python Exercises\\2 Duplicated\\duplicated_data.csv', index=False, header=False)
print(df_state)
CodePudding user response:
This is happening because .duplicated returns a boolean series (True/False), which you are saving directly.
But you should be using this to subset the data, like so:
import pandas as pd
import os
df_state = pd.DataFrame(
[["3 Liu Yu,876"],
["4 Koh chong,123"],
["3 Liu Yu,876"]])
df_state = df_state[0].str.split(" ", expand= True)
print(df_state, "\n")
duplicated = df_state.duplicated() # just a boolean series
print(duplicated, "\n")
print(df_state[duplicated], "\n") ## <- subset and save with .to_csv
# as Anders Källmar points out, you can also do this:
all_duplicated = df_state.duplicated(keep= False)
print(df_state[all_duplicated])
Output:
0 1 2
0 3 Liu Yu,876
1 4 Koh chong,123
2 3 Liu Yu,876
0 False
1 False
2 True
dtype: bool
0 1 2
2 3 Liu Yu,876
0 1 2
0 3 Liu Yu,876
2 3 Liu Yu,876
CodePudding user response:
Use df.duplicated with keep=False to get a boolean mask of your dup rows then extract rows:
df = pd.read_csv('sample_dup.csv', header=None)
print(df)
0 1
0 CAIN TAN 86092142
1 YEO KIAT JUN 81901613
2 LIU YU YEE 89267062 # dup group 1 (1/2)
3 KOH CHONG YONG 89087115 # dup group 2 (1/3)
4 ROGER KOH KIAT 85875432
5 ONG JUN KANG 82065756
6 LIU YU YEE 89267062 # dup group 1 (2/2)
7 CHEW CHONG JIE 88326589
8 KOH CHONG YONG 89087115 # dup group 2 (2/3)
9 LEE SENG RI 87050554
10 ZHOU JING SHU 87204345
11 LOY KOH KE 83824725
12 WONG KANG SENG 88391206
13 CHEW KIAT KIAT 89209079
14 KOH CHONG YONG 89087115 # dup group 2 (3/3)
# 0 for your first column
>>> df[df[0].duplicated(keep=False)]
0 1
2 LIU YU YEE 89267062
3 KOH CHONG YONG 89087115
6 LIU YU YEE 89267062
8 KOH CHONG YONG 89087115
14 KOH CHONG YONG 89087115