A Google Sheet has multi-line information in its cells, e.g. address.
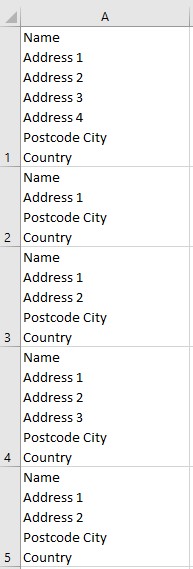
Each address can have a different number of lines, but we know:
1st line is always the name
Penultimate line is always the post code and city
Last line is always the country
And we are trying to split the address into 4 columns:
Name
Street address (i.e. the address left over after extracting name, post code & city, country)
Post code and city
Country
So col B (name) reads first line =REGEXEXTRACT(A1,”(\w.*)”)
Of course, I can figure out how many lines there are in each cell by counting next line character
=LEN(A1)-LEN(SUBSTITUTE(A1,CHAR(10),””))
If the formula returns 6, then there are 7 lines
How do we get columns C (street address), D (postcode and city) and E (country) formulaically?
I mean, sure, I can get country for this cell with
=REGEXEXTRACT(A2,”(\n.*){6}”)
but I can’t copy the formula over….the 6 above is manual input, which defeats the purpose. Since this is regex, it obviously can’t take cell references instead of 6, e.g.
=REGEXEXTRACT(Amazon!B4,”(\n.*){F1}”)
(if for example, I stored in column F the number of next line characters in column A)
CodePudding user response:
try:
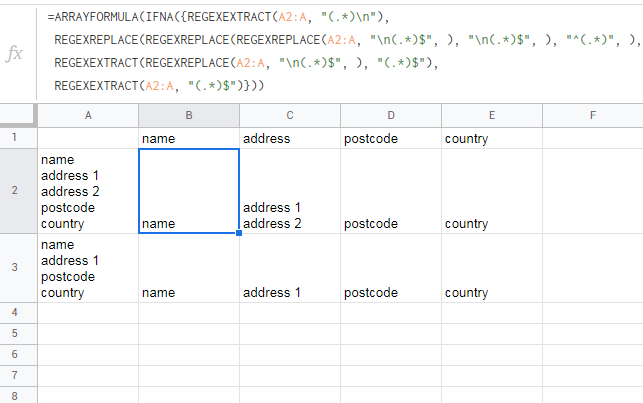
=ARRAYFORMULA(IFNA({REGEXEXTRACT(A2:A, "(.*)\n"),
REGEXREPLACE(REGEXREPLACE(REGEXREPLACE(A2:A, "\n(.*)$", ), "\n(.*)$", ), "^(.*)\n", ),
REGEXEXTRACT(REGEXREPLACE(A2:A, "\n(.*)$", ), "(.*)$"),
REGEXEXTRACT(A2:A, "(.*)$")}))