I have the conditions to fill a new column defined in a string.
condition_string = "colA='yes' & colB='yes' & (colC='yes' | colD='yes'): 'Yes', colA='no' & colB='no' & (colC='no' | colD='no'): 'No', ELSE : 'UNKNOWN'"
The string can be re-written/structured in any other format (dictionary) and then be fed into the code to get the end result.
The dataframe is
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB03', 'AB04','AB05', 'AB06'],
'colA': ["yes","yes",'yes',"no","no",'yes', np.nan],
'colB': [np.nan,'yes','yes',"no",'no', np.nan, "yes"],
'colC': ["yes",'yes', 'yes',"no", "no",np.nan,np.nan],
'colD': ["yes",'no', 'yes',"no",np.nan,"no",np.nan],
}
)
The end result should look like this
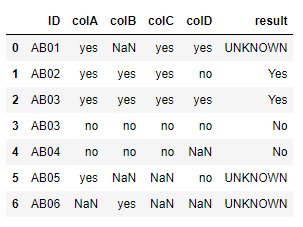
How can I get this done without hardcoding the stuff in the condition_string. Or do you have any ways in which the condition_string can be restructured and then apply to the dataframe?
UPDATE: What if the dictionary is like?
condition_string = "colA='yes' & (colB='yes' | colB='no)' &
(colC='yes' | colD='yes'): 'Yes', colA='no' & colB='no' & (colC='no' | colD='no'): 'No', ELSE : 'UNKNOWN'"
and the dataframe is like
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB03', 'AB04','AB05', 'AB06'],
'colA': ["yes","yes",'yes',"no","no",'yes', np.nan],
'colB': ["no",'yes','yes',"no",'no', np.nan, "yes"],
'colC': ["yes",'yes', 'yes',"no", "no",np.nan,np.nan],
'colD': ["yes",'no', 'yes',"no",np.nan,"no",np.nan]
}
)
CodePudding user response:
You can use np.where:
df['results'] = np.where((((df['colA']=='yes') & (df['colB']=='yes')) & ((df['colC']=='yes') | (df['colD']=='yes'))), 'Yes',np.where(((df['colA']=='no') & (df['colB']=='no')) & ((df['colC']=='no' )| (df['colD']=='no')), 'No','UNKNOWN'))
which gives:
ID colA colB colC colD decision
0 AB01 yes NaN yes yes UNKNOWN
1 AB02 yes yes yes no Yes
2 AB03 yes yes yes yes Yes
3 AB03 no no no no No
4 AB04 no no no NaN No
5 AB05 yes NaN NaN no UNKNOWN
6 AB06 NaN yes NaN NaN UNKNOWN
CodePudding user response:
IIUC you want to create arbitrary conditions for your df, which can be done using functools.reduce and operator.and_. You can then set up your conditions using two lists (instead of a dict), first one being the columns, second one the string to test against and finally np.select:
from functools import reduce
from operator import and_
cols = ["colA", "colB", ["colC", "colD"]] # group the cols in a list if they belong to the same group
answer = ["yes", "no"]
conds = [reduce(and_, [df[i].eq(ans) if isinstance(i, str) else df[i].eq(ans).any(1)
for i in cols]) for ans in answer]
df["result"] = np.select(conds, answer, "Unknown")
print (df)
ID colA colB colC colD result
0 AB01 yes NaN yes yes Unknown
1 AB02 yes yes yes no yes
2 AB03 yes yes yes yes yes
3 AB03 no no no no no
4 AB04 no no no NaN no
5 AB05 yes NaN NaN no Unknown
6 AB06 NaN yes NaN NaN Unknown
Now you simply need to edit the two lists cols and answer if you need to adjust your conditions.
CodePudding user response:
Here a solution to convert your condition to a python function and then applying it to the rows of your DataFrame:
import re
condition_string = "colA='yes' & colB='yes' & (colC='yes' | colD='yes'): 'Yes', colA='no' & colB='no' & (colC='no' | colD='no'): 'No', ELSE : 'UNKNOWN'"
# formatting string as python function apply_cond
col_pattern = re.compile(r'(\w )=')
cond_form = re.sub(r', (?!ELSE)', '\n\telif ', condition_string) \
.replace(": ", ":\n\t\treturn ") \
.replace(", ELSE ", "\n\telse") \
.replace("&", "and") \
.replace('|', 'or')
cond_form = re.sub(col_pattern, r"row['\1']==", cond_form)
function_def = "def apply_cond(row):\n\tif " cond_form
#print(function_def) # uncomment to see how the function is defined
# executing the function definition of apply_cond
exec(function_def)
# applying the function to each row
df["result"]=df.apply(lambda x: apply_cond(x), axis=1)
print(df)
Output:
ID colA colB colC colD result
0 AB01 yes NaN yes yes UNKNOWN
1 AB02 yes yes yes no Yes
2 AB03 yes yes yes yes Yes
3 AB03 no no no no No
4 AB04 no no no NaN No
5 AB05 yes NaN NaN no UNKNOWN
6 AB06 NaN yes NaN NaN UNKNOWN
You might want to adapt string formatting depending on condition_string (I did it quickly, there might be some unsupported combinations) but if you get those strings automatically it will save you from defining them all over again.