In the data set I'm working on, each unique ID has a Total Pay. I've summed this Total pay up per ID by using
df['Total Courier Pay'] = df.groupby(['ID'])['Total Pay'].transform(sum)
df
The output in the excel sheet looks like this:
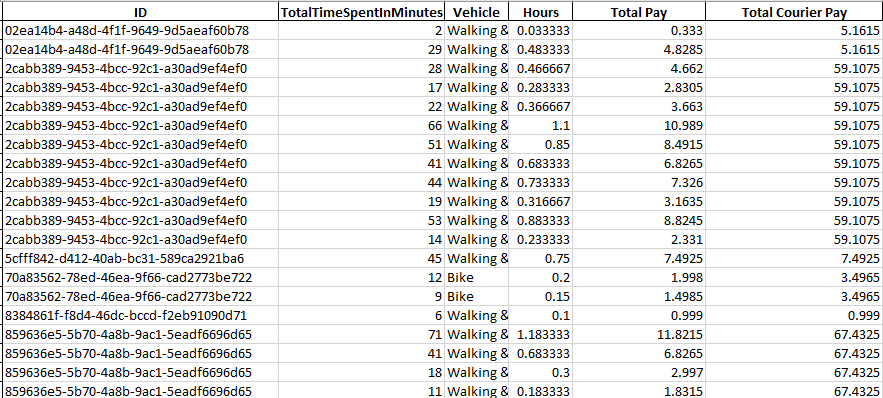
I'm happy to keep all the columns shown but is there any way to clean it up so it looks more like this instead of having duplicate rows for each ID?:
ID Total Courier Pay
1 5.1615
2 59.1075
3 7.4925
Is it possible to create a new sheet in the same workbook where it only displays the ID and Total Courier Pay?
Thanks in advance!
CodePudding user response:
df['Total Courier Pay'] = df.groupby(['ID'])['Total Pay'].transform(sum)
new_df = df.drop_duplicates(subset=['ID'])[['ID','Total Courier Pay']]
CodePudding user response:
After some help from @Pedro Maia and reading some other forums, this seemed to work for me:
df.drop_duplicates('ID', inplace=True)
Thanks for the help :) - This will change the current excel sheet rather than create a new one.
CodePudding user response:
According to your example, it seems that you want to create a separate DataFrame with only the 'ID' and 'Total Courier Pay'. In that case, you can do
total_pay_by_ID = (
df.groupby('ID', as_index=False)['Total Pay']
.sum()
.rename(columns={'Total Pay': 'Total Courier Pay'})
)
Is it possible to create a new sheet in the same workbook where it only displays the ID and Total Courier Pay?
To save it to a new sheet 'sheet_name' of an existing excel file 'path/to/excel/file.xlsx' you can do
with pd.ExcelWriter('path/to/excel/file.xlsx', mode='a') as writer:
total_pay_by_ID.to_excel(writer, sheet_name='sheet_name')