I have a dataset that looks like this:
Year Type Country Size
1900 1 A 300
1901 1 A 359
1902 1 A 839
1903 1 A 35
1900 2 B 1235
1904 3 C 75
1901 4 B 100
1902 4 B 467
1903 4 B 2356
1904 4 B 6940
1905 4 B 34
1910 5 A 3424
1-5 are different types
A-D are different countries
For some types (such as type 1) I have 4 years of consecutive data. For other (such as type 3) I only have 1 year of info. In the real data frame, for some types, I have 40 years of data.
Each type has a correspondent country, and I have a total of 5 different countries.
(In reality, this database is >10k lines and >15 countries.)
I would like to print a table that is presentable, with a formal layout which would tell me:
- How many unique types exist per country (Eg. country C=1, Country A=5 )
- Total Size per country, which sums all sizes per country (eg. country C = 175)
Thanks
CodePudding user response:
I guess this is what you are looking for:
- Code
library(data.table)
setDT(df)[, .(N = .N, Size = sum(Size)), by = .(Country)]
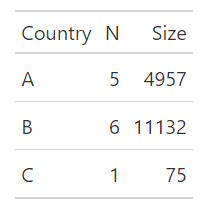
- Output
#> Country N Size
#> 1: A 5 4957
#> 2: B 6 11132
#> 3: C 1 75
- Your data
df <- data.frame(Year = c(1900,1901,1902,1903,1900,1904,1901,1902,1903,1904,1905,1910),
Type = c(1,1,1,1,2,3,4,4,4,4,4,5),
Country = c("A","A","A","A","B","C","B","B","B","B","B","A"),
Size = c(300,359,839,35,1235,75,100,467,2356,6940,34,3424))
Created on 2021-11-01 by the