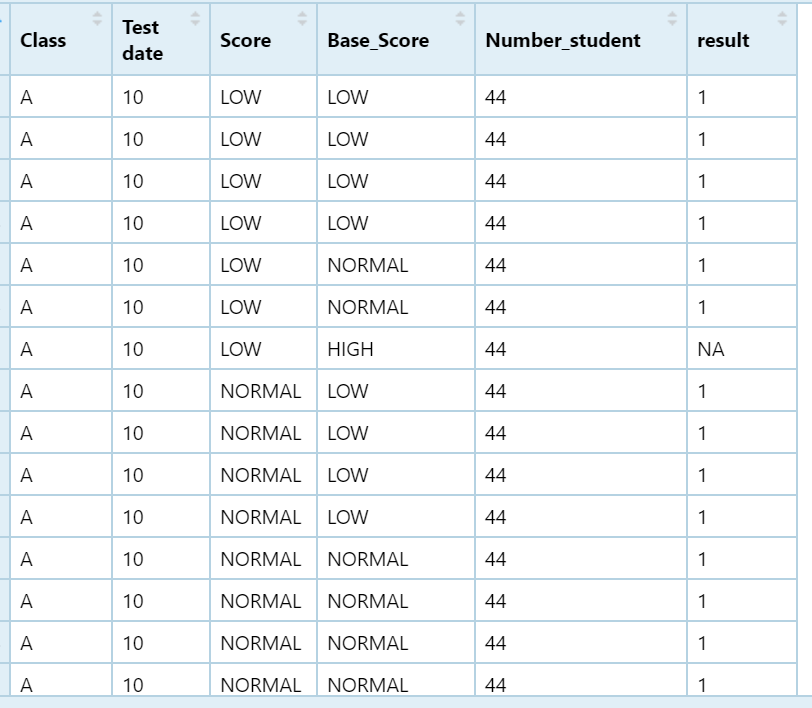
I have a df that looks like this:
I would like to use pivot_wider to summarize it to a wider format. The expected results will looks like this:

But my outcome looks like this:

Instead of adding each count, it put each 1 as character. What did I do wrong?
My sample data and the codes to build above table are:
df<-structure(list(Class = c("A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A"), `Test date` = c(10,
10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10,
10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10), Score = c("LOW",
"LOW", "LOW", "LOW", "LOW", "LOW", "LOW", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "HIGH", "HIGH", "HIGH", "HIGH", "HIGH", "HIGH"
), Base_Score = c("LOW", "LOW", "LOW", "LOW", "NORMAL", "NORMAL",
"HIGH", "LOW", "LOW", "LOW", "LOW", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL", "NORMAL",
"NORMAL", "NORMAL", "HIGH", "HIGH", "LOW", "NORMAL", "NORMAL",
"NORMAL", "HIGH", "HIGH"), Number_student = c(44, 44, 44, 44,
44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44,
44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44, 44,
44, 44, 44, 44, 44, 44, 44, 44, 44), result = c("1", "1", "1",
"1", "1", "1", "NA", "1", "1", "1", "1", "1", "1", "1", "1",
"1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",
"1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",
"1", "1", "1", "1")), row.names = c(NA, -45L), class = c("tbl_df",
"tbl", "data.frame"))
df %>%
mutate(result=as.numeric(df))%>%
pivot_wider(names_from = Base_Score,
values_from = result)
CodePudding user response:
We need the values_fn to do the sum. If there are duplicate elements, by default, the pivot_wider returns list columns
library(dplyr)
library(tidyr)
df %>%
mutate(result = as.numeric(result)) %>%
pivot_wider(names_from = Base_Score,
values_from = result, values_fn = list(result = sum))
-output
# A tibble: 3 × 7
Class `Test date` Score Number_student LOW NORMAL HIGH
<chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
1 A 10 LOW 44 4 2 NA
2 A 10 NORMAL 44 4 26 2
3 A 10 HIGH 44 1 3 2