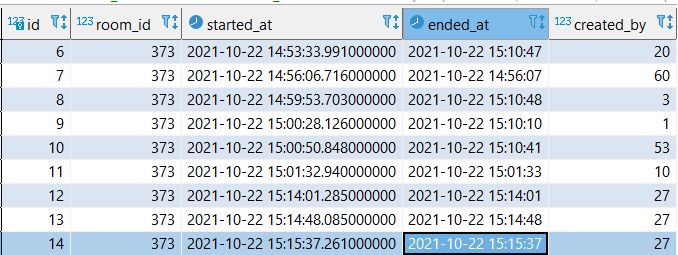
I have this data. This is a record of meeting time
Created_by is user_id
I want to count the total hours of room used. The system add new data based on every user that join the room.
So, actually the meeting in this room has 4 sessions, which is:
- 14:53:33 (id 6) until 15:10:48 (id 8)
- 15:14:01 (id 12) until 15:15:37 (id 12)
- 15:14:48 (id 13) until 15:14:48 (id 13)
- 15:15:37 (id 14) until 15:15:37 (id 14)
I need the result to be 4 rows like above, instead of 10 rows like the data.
Room session 2-4 is just user 27 trying to testing the room
After some breakdown, the condition has to fulfill is like this :
1. grouping by room_id
2. check if :
a. record first started at (FSA) and first ended at (FEA)
CONDITION:
A. If
started at between FSA and FEA
AND
ended at between FSA and FEA
THEN
CONTINUE
B. If
started at between FSA and FEA
AND
ended at > FEA
replace FEA with new ended_at
C. If
started at > FEA
AND
ended at > FEA
THEN
append new row and record new FSA and new FEA
Can you recommend the query that looping to compare in order the meet the conditions above ?
I'm having trouble finding the right query.
Please share your thoughts on this problem.
Cheers, Thankyou.
CodePudding user response:
Nested queries to find the result:
- tagged - find rows after which is a new session
- summarized - mark rows in the same session
with tagged
as (
select *, case when lead(started_at) over w < max(ended_at) over w then 0 else 1 end tag, row_number() over w as rn
from meeting
window w as (partition by room_id order by started_at asc)
),
summarized
as (
select *, sum(tag) over (partition by room_id order by rn desc) tag_summary
from tagged
)
select room_id, min(started_at) started_at, max(ended_at) ended_at
from summarized
group by room_id, tag_summary
order by room_id, started_at
;
-- data scripts
create table meeting (
id int unsigned primary key auto_increment,
room_id int unsigned not null,
started_at datetime not null,
ended_at datetime not null
);
insert into meeting ( room_id, started_at, ended_at )
values
( 373, '2021-10-22 14:53:33', '2021-10-22 15:10:47')
, ( 373, '2021-10-22 14:56:06', '2021-10-22 14:56:47')
, ( 373, '2021-10-22 14:59:53', '2021-10-22 15:10:48')
, ( 373, '2021-10-22 15:00:28', '2021-10-22 15:10:10')
, ( 373, '2021-10-22 15:00:50', '2021-10-22 15:10:41')
, ( 373, '2021-10-22 15:01:32', '2021-10-22 15:01:33')
, ( 373, '2021-10-22 15:14:01', '2021-10-22 15:14:01')
, ( 373, '2021-10-22 15:14:24', '2021-10-22 15:14:48')
, ( 373, '2021-10-22 15:15:37', '2021-10-22 15:15:37')
;
https://dbfiddle.uk/?rdbms=mysql_8.0&fiddle=cca43c3937be7a884dc906615b5a9c3a
CodePudding user response:
3.6.5.5 LOOP Statement
[begin_label:] LOOP
statement_list
END LOOP [end_label]
LOOP implements a simple loop construct, enabling repeated execution of the statement list, which consists of one or more statements, each terminated by a semicolon (;) statement delimiter. The statements within the loop are repeated until the loop is terminated. Usually, this is accomplished with a LEAVE statement. Within a stored function, RETURN can also be used, which exits the function entirely.
Neglecting to include a loop-termination statement results in an infinite loop.
A LOOP statement can be labelled. For the rules regarding label use, see Section 13.6.2, “Statement Labels”.
Example:
CREATE PROCEDURE doiterate(p1 INT)
BEGIN
label1: LOOP
SET p1 = p1 1;
IF p1 < 10 THEN
ITERATE label1;
END IF;
LEAVE label1;
END LOOP label1;
SET @x = p1;
END;