I have a pandas dataframe that is in the following format:
This contains the % change in stock prices each day for 3 companies MSFT, F and BAC.
I would like to use a OneClassSVM calculator to detect whether the data is an outlier or not. I have tried the following code, which I believe detects the rows which contain outliers.
#Import libraries
from sklearn.svm import OneClassSVM
import matplotlib.pyplot as plt
#Create SVM Classifier
svm = OneClassSVM(kernel='rbf',
gamma=0.001, nu=0.03)
#Use svm to fit and predict
svm.fit(delta)
pred = svm.predict(delta)
#If the values are outlier the prediction
#would be -1
outliers = where(pred==-1)
#Print rows with outliers
print(outliers)
This gives the following output:

I would like to then add a new column to my dataframe that includes whether the data is an outlier or not. I have tried the following code but I get an error due to the lists being different lengths as shown below.
condition = (delta.index.isin(outliers))
assigned_value = "outlier"
df['isoutlier'] = np.select(condition,
assigned_value)
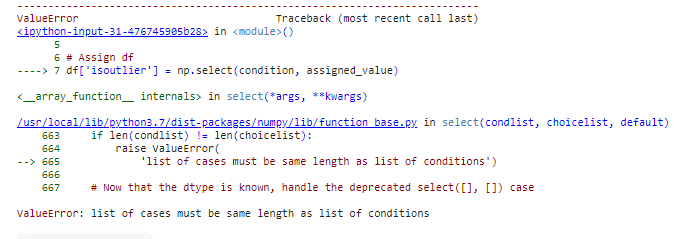
Would you be able to let me know I could add this column given that the list of the rows containing outliers is much shorter please?
CodePudding user response:
It's not very clear what is delta and df in your code. I am assuming they are the same data frame.
You can use the result from svm.predict , here we leave it as blank '' if not outlier:
import numpy as np
df = pd.DataFrame(np.random.uniform(0,1,(100,3)),columns=['A','B','C'])
svm = OneClassSVM(kernel='rbf', gamma=0.001, nu=0.03)
svm.fit(df)
pred = svm.predict(df)
df['isoutlier'] = np.where(pred == -1 ,'outlier','')
A B C isoutlier
0 0.869475 0.752420 0.388898
1 0.177420 0.694438 0.129073
2 0.011222 0.245425 0.417329
3 0.791647 0.265672 0.401144
4 0.538580 0.252193 0.142094
.. ... ... ... ...
95 0.742192 0.079426 0.676820 outlier
96 0.619767 0.702513 0.734390
97 0.872848 0.251184 0.887500 outlier
98 0.950669 0.444553 0.088101
99 0.209207 0.882629 0.184912