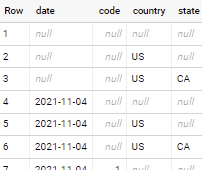
Is there a way to accomplish the following in BigQuery? This syntax is supported in a DB such as 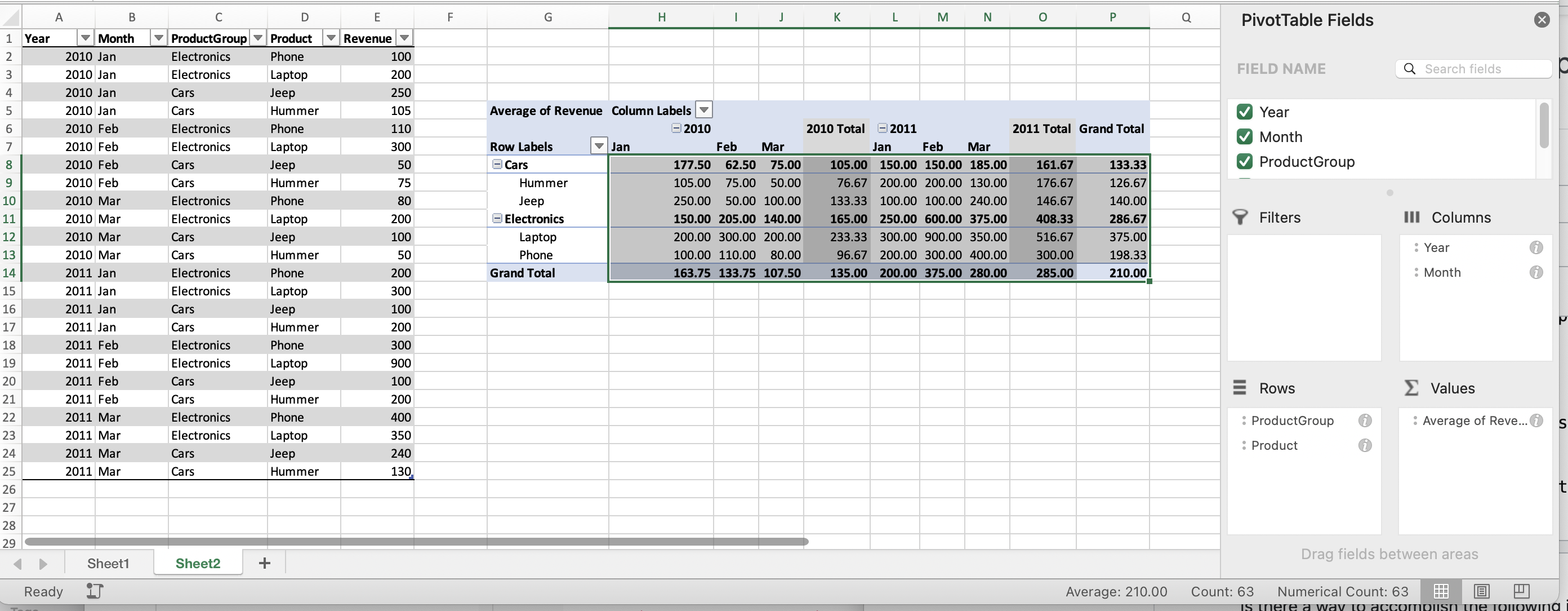
Note that the Pivot table has 63 value cells.
Now, the correct SQL syntax for this is as follows in the verbose GROUP BY-only syntax:
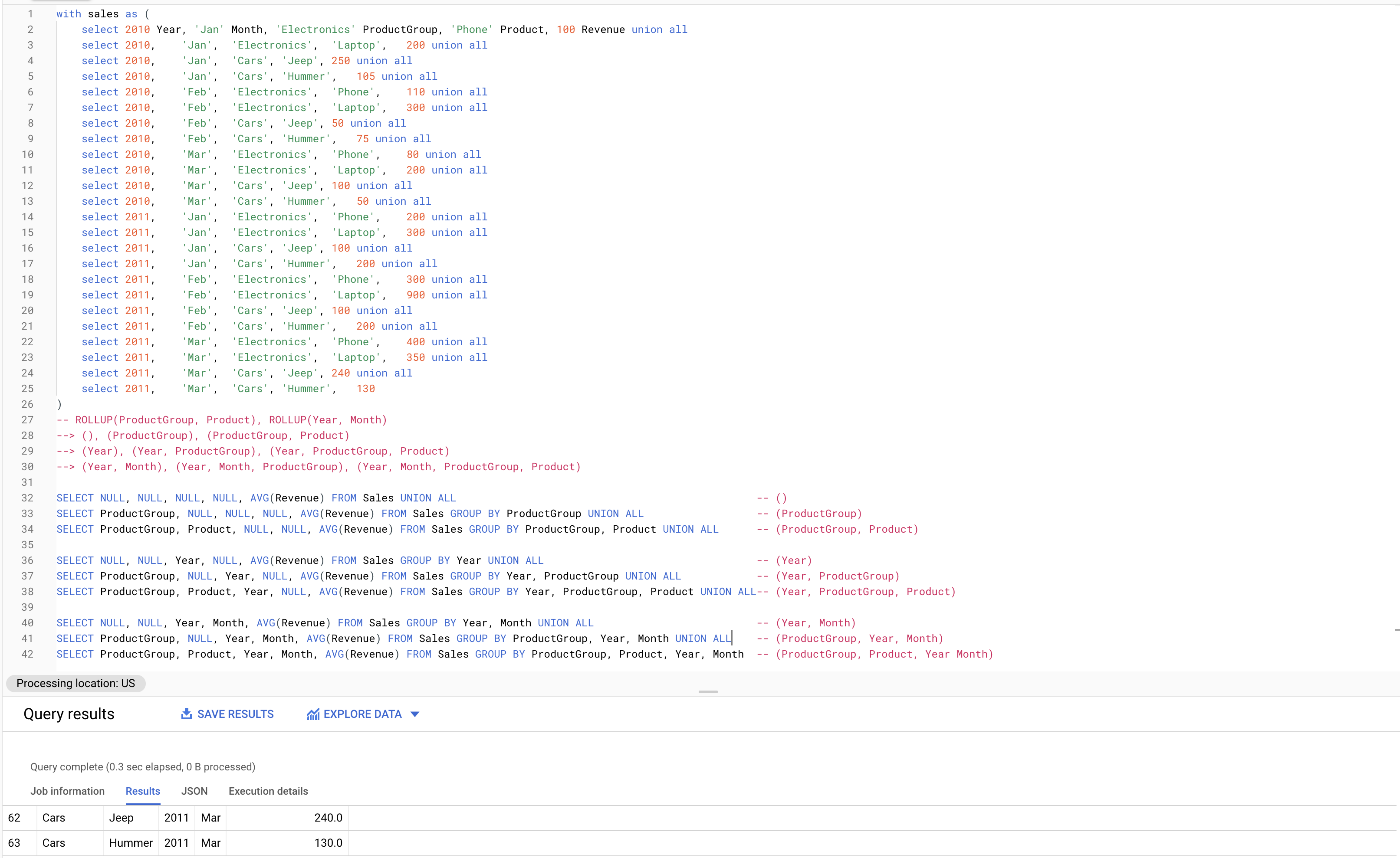
Notice that this also produces exactly 63 rows (and since we have one value column -- SUM Revenue -- 63 rows x 1 col = 63 value cells). The query is the following:
with sales as (
select 2010 Year, 'Jan' Month, 'Electronics' ProductGroup, 'Phone' Product, 100 Revenue union all
select 2010, 'Jan', 'Electronics', 'Laptop', 200 union all
select 2010, 'Jan', 'Cars', 'Jeep', 250 union all
select 2010, 'Jan', 'Cars', 'Hummer', 105 union all
select 2010, 'Feb', 'Electronics', 'Phone', 110 union all
select 2010, 'Feb', 'Electronics', 'Laptop', 300 union all
select 2010, 'Feb', 'Cars', 'Jeep', 50 union all
select 2010, 'Feb', 'Cars', 'Hummer', 75 union all
select 2010, 'Mar', 'Electronics', 'Phone', 80 union all
select 2010, 'Mar', 'Electronics', 'Laptop', 200 union all
select 2010, 'Mar', 'Cars', 'Jeep', 100 union all
select 2010, 'Mar', 'Cars', 'Hummer', 50 union all
select 2011, 'Jan', 'Electronics', 'Phone', 200 union all
select 2011, 'Jan', 'Electronics', 'Laptop', 300 union all
select 2011, 'Jan', 'Cars', 'Jeep', 100 union all
select 2011, 'Jan', 'Cars', 'Hummer', 200 union all
select 2011, 'Feb', 'Electronics', 'Phone', 300 union all
select 2011, 'Feb', 'Electronics', 'Laptop', 900 union all
select 2011, 'Feb', 'Cars', 'Jeep', 100 union all
select 2011, 'Feb', 'Cars', 'Hummer', 200 union all
select 2011, 'Mar', 'Electronics', 'Phone', 400 union all
select 2011, 'Mar', 'Electronics', 'Laptop', 350 union all
select 2011, 'Mar', 'Cars', 'Jeep', 240 union all
select 2011, 'Mar', 'Cars', 'Hummer', 130
)
-- ROLLUP(ProductGroup, Product), ROLLUP(Year, Month)
--> (), (ProductGroup), (ProductGroup, Product)
--> (Year), (Year, ProductGroup), (Year, ProductGroup, Product)
--> (Year, Month), (Year, Month, ProductGroup), (Year, Month, ProductGroup, Product)
SELECT NULL, NULL, NULL, NULL, AVG(Revenue) FROM Sales UNION ALL -- ()
SELECT ProductGroup, NULL, NULL, NULL, AVG(Revenue) FROM Sales GROUP BY ProductGroup UNION ALL -- (ProductGroup)
SELECT ProductGroup, Product, NULL, NULL, AVG(Revenue) FROM Sales GROUP BY ProductGroup, Product UNION ALL -- (ProductGroup, Product)
SELECT NULL, NULL, Year, NULL, AVG(Revenue) FROM Sales GROUP BY Year UNION ALL -- (Year)
SELECT ProductGroup, NULL, Year, NULL, AVG(Revenue) FROM Sales GROUP BY Year, ProductGroup UNION ALL -- (Year, ProductGroup)
SELECT ProductGroup, Product, Year, NULL, AVG(Revenue) FROM Sales GROUP BY Year, ProductGroup, Product UNION ALL-- (Year, ProductGroup, Product)
SELECT NULL, NULL, Year, Month, AVG(Revenue) FROM Sales GROUP BY Year, Month UNION ALL -- (Year, Month)
SELECT ProductGroup, NULL, Year, Month, AVG(Revenue) FROM Sales GROUP BY ProductGroup, Year, Month UNION ALL -- (ProductGroup, Year, Month)
SELECT ProductGroup, Product, Year, Month, AVG(Revenue) FROM Sales GROUP BY ProductGroup, Product, Year, Month -- (ProductGroup, Product, Year Month)
However, this query is really a nightmare to product -- even if generated programatically -- as there may be an order by, subselect, ... etc and union-ing all those statements together could potentially turn into a monstrous construction (for example, a 3 rows x 3 cols construction with a 100-line SQL statement would become 4^2 * 100 lines of sql, and 5x5 would be 5^2 * 100 lines, etc. if my math is correct).
What would be the proper way to do this then? Note that in a database like Postgres the following works as-is:
SELECT ProductGroup, Product, Year, Month, AVG(Revenue) FROM Sales GROUP BY ROLLUP(ProductGroup, Product), ROLLUP(Year, Month);
Here is the Saved Query if you want to use this as a starting point: 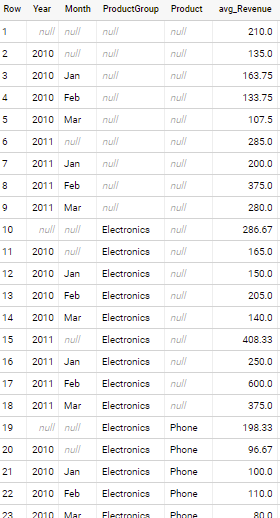
CodePudding user response:
Similar to my previous answer, but without CASE expressions 'blocking' use of indexes.
It still processes 9x as much data though, but probably more quickly than the CASE based approach.
WITH
rollup_pg_p AS
(
SELECT ProductGroup, Product, Year, Month, Revenue FROM Sales
UNION ALL SELECT ProductGroup, NULL, Year, Month, Revenue FROM Sales
UNION ALL SELECT NULL, NULL, Year, Month, Revenue FROM Sales
),
rollup_y_m AS
(
SELECT ProductGroup, Product, Year, Month, Revenue FROM rollup_pg_p
UNION ALL SELECT ProductGroup, Product, Year, NULL, Revenue FROM rollup_pg_p
UNION ALL SELECT ProductGroup, Product, NULL, NULL, Revenue FROM rollup_pg_p
)
SELECT
ProductGroup, Product, Year, Month, AVG(Revenue) FROM rollup_y_m
GROUP BY
1, 2, 3, 4
ORDER BY
1, 2, 3, 4
Edit: An elaboration.
Your query is this (- is my shorthand for NULL in pseudocode)...
SELECT a, b, c, d, AVG(x) FROM src GROUP BY a, b, c, d
UNION ALL SELECT a, b, c, -, AVG(x) FROM src GROUP BY a, b, c
UNION ALL SELECT a, b, -, -, AVG(x) FROM src GROUP BY a, b
UNION ALL SELECT a, -, c, d, AVG(x) FROM src GROUP BY a, c, d
UNION ALL SELECT a, -, c, -, AVG(x) FROM src GROUP BY a, c
UNION ALL SELECT a, -, -, -, AVG(x) FROM src GROUP BY a
UNION ALL SELECT -, -, c, d, AVG(x) FROM src GROUP BY c, d
UNION ALL SELECT -, -, c, -, AVG(x) FROM src GROUP BY c
UNION ALL SELECT -, -, -, -, AVG(x) FROM src
Which is functionally the same as this...
WITH
combinations AS (
SELECT a, b, c, d, x FROM src
UNION ALL SELECT a, b, c, -, x FROM src
UNION ALL SELECT a, b, -, -, x FROM src
UNION ALL SELECT a, -, c, d, x FROM src
UNION ALL SELECT a, -, c, -, x FROM src
UNION ALL SELECT a, -, -, -, x FROM src
UNION ALL SELECT -, -, c, d, x FROM src
UNION ALL SELECT -, -, c, -, x FROM src
UNION ALL SELECT -, -, -, -, x FROM src
)
SELECT a, b, c, d, AVG(x) FROM combinations GROUP BY a, b, c, d
The advantage of the latter is that the aggregate (or aggregates) that you want to apply are only written once, as is the GROUP BY.
This still requires enumerating all 9 combinations.
So, the answer at the start is just a short hand way of enumerating the 9 combinations. Not much shorter, but slightly. And would be even more valuable if you needed ROLLUP(a, b), ROLLUP(c, d), ROLLUP(e, f) (Writing 3 combinations for each ROLLUP(), for 9 in total, to generate 27 combinations.)
CodePudding user response:
Back to my original answer of grouping twice...
WITH
rollup_pg_p AS
(
SELECT
ProductGroup, Product, 1 AS dummy, Year, Month, SUM(Revenue) AS sum_rev, COUNT(Revenue) AS cnt_row
FROM
Sales
GROUP BY
ROLLUP(Year, Month, ProductGroup, Product)
HAVING
Month IS NOT NULL -- This prevents the roll up going further than desired
-- Effectively giving `GROUP BY Year, Month, ROLLUP(ProductGroup, Product)
)
SELECT
ProductGroup, Product, Year, Month, SUM(sum_rev) / SUM(cnt_row)
FROM
rollup_pg_p
GROUP BY
ROLLUP(ProductGroup, Product, Dummy, Year, Month)
HAVING
dummy IS NOT NULL -- Same 'trick' again, but we created the dummy column
-- as ProductGroup and Product CAN legitimately be NULL at this point.
ORDER BY
1, 2, 3, 4
(NOTE: Other dialects would use WHERE NOT GROUPING(Product), so avoid the need for the dummy column, but BigQuery doesn't appear to have that functionality either...)
Still has the downside of not working for some aggregates, but might be meaningfully faster than the alternative approaches.
CodePudding user response:
I want the cross product of the two rollups:
Consider below
select * from (
select date, code
from `first-outlet-750.tests.parq_stored`
group by rollup(date, code)
), (
select country, state
from `first-outlet-750.tests.parq_stored`
group by rollup(country, state))
with output like below