I have two dataframes:
Table1:
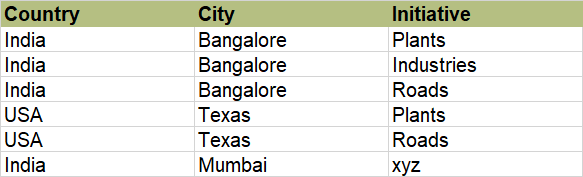
Table2:
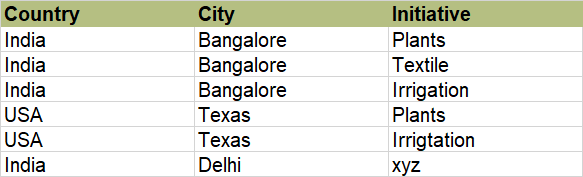
How to find:
- The country-city combinations that are present only in Table2 but not Table1. Here [India-Mumbai] is the output.
- For each country-city combination, that's present in both the tables, find the "Initiatives" that are present in Table2 but not Table1. Here {"India-Bangalore": [Textile, Irrigation], "USA-Texas": [Irrigation]}
CodePudding user response:
To answer the first question, we can use the merge method and keep only the NaN rows :
>>> df_merged = pd.merge(df_1, df_2, on=['Country', 'City'], how='left', suffixes = ['_1', '_2'])
>>> df_merged[df_merged['Initiative_2'].isnull()][['Country', 'City']]
Country City
13 India Mumbai
For the next question, we first need to remove the NaN rows from the previously merged DataFrame :
>>> df_both_table = df_merged[~df_merged['Initiative_2'].isnull()]
>>> df_both_table
Country City Initiative_1 Initiative_2
0 India Bangalore Plants Plants
1 India Bangalore Plants Textile
2 India Bangalore Plants Irrigtion
3 India Bangalore Industries Plants
4 India Bangalore Industries Textile
5 India Bangalore Industries Irrigtion
6 India Bangalore Roads Plants
7 India Bangalore Roads Textile
8 India Bangalore Roads Irrigtion
9 USA Texas Plants Plants
10 USA Texas Plants Irrigation
11 USA Texas Roads Plants
12 USA Texas Roads Irrigation
Then, we can filter on the rows that are strictly different on columns Initiative_1 and Initiative_2 and use a groupby to get the list of Innitiative_2 :
>>> df_unique_initiative_2 = df_both_table[~(df_both_table['Initiative_1'] == df_both_table['Initiative_2'])]
>>> df_list_initiative_2 = df_unique_initiative_2.groupby(['Country', 'City'])['Initiative_2'].unique().reset_index()
>>> df_list_initiative_2
Country City Initiative_2
0 India Bangalore [Textile, Irrigation, Plants]
1 USA Texas [Irrigation, Plants]
We do the same but this time on Initiative_1 to get the list as well :
>>> df_list_initiative_1 = df_unique_initiative_2.groupby(['Country', 'City'])['Initiative_1'].unique().reset_index()
>>> df_list_initiative_1
Country City Initiative_1
0 India Bangalore [Plants, Industries, Roads]
1 USA Texas [Plants, Roads]
To finish, we use the set to remove the last redondant Initiative_1 elements to get the expected result :
>>> df_list_initiative_2['Initiative'] = (df_list_initiative_2['Initiative_2'].map(set)-df_list_initiative_1['Initiative_1'].map(set)).map(list)
>>> df_list_initiative_2[['Country', 'City', 'Initiative']]
Country City Initiative
0 India Bangalore [Textile, Irrigation]
1 USA Texas [Irrigation]
CodePudding user response:
Alternative approach (df1 your Table1, df2 your Table2):
combos_1, combos_2 = set(zip(df1.Country, df1.City)), set(zip(df2.Country, df2.City))
in_2_but_not_in_1 = [f"{country}-{city}" for country, city in combos_2 - combos_1]
initiatives = {
f"{country}-{city}": (
set(df2.Initiative[df2.Country.eq(country) & df2.City.eq(city)])
- set(df1.Initiative[df1.Country.eq(country) & df1.City.eq(city)])
)
for country, city in combos_1 & combos_2
}
Results:
['India-Delhi']
{'India-Bangalore': {'Irrigation', 'Textile'}, 'USA-Texas': {'Irrigation'}}
I think you got this "The country-city combinations that are present only in Table2 but not Table1. Here [India-Mumbai] is the output" wrong: The combinations India-Mumbai is not present in Table2?