I have a table with duplicate entries which I want to remove, keeping none but one of the duplicate entries. As you can see, they are exactly the same in every colum, there's no way to differentiate them:
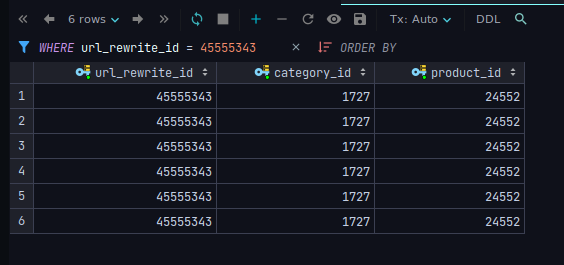
I've used this query to figure out how many duplicates I have:
select url_rewrite_id, category_id, product_id, count(*) cnt
from catalog_url_rewrite_product_category
group by url_rewrite_id, category_id, product_id
having cnt > 1
order by cnt desc
I could use a variant of this to remove all duplicates:
delete
from catalog_url_rewrite_product_category
where url_rewrite_id in (
select url_rewrite_id
from catalog_url_rewrite_product_category
group by url_rewrite_id, category_id, product_id
having count(*) > 1
)
The problem I have with this is it would remove all entries that are duplicates and wouldn't keep the last one.
Earlier questions (here and here) assume a unique id column of sorts which is not the case with the data structure I have.
CodePudding user response:
Have you tried one of the solutions I read in the thread you shared (here)?
ALTER IGNORE TABLE jobs
ADD UNIQUE INDEX idx_name (site_id, title, company);
I think this would work.