Python 3.10 with Pandas 1.3.4
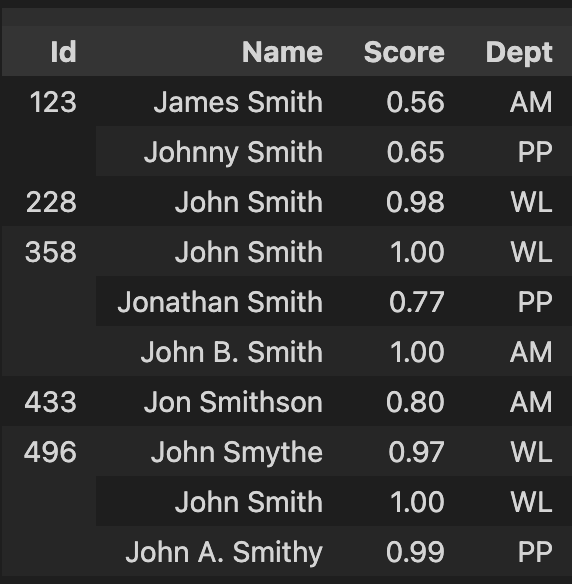
Using the following code I create a dataframe, and then sort it to "group" the Id's together, and only display each unique Id one time.
import pandas as pd
arrays = [['123', '228', '358', '123', '358', '358','433','496', '496', '496'],
['James Smith', 'John Smith', 'John Smith', 'Johnny Smith', 'Jonathan Smith', 'John B. Smith', 'Jon Smithson', 'John Smythe','John Smith', 'John A. Smithy'],
[0.56, 0.98, 1.0, 0.65, 0.77, 1.0, 0.80, 0.97, 1.0, 0.99],
['AM', 'WL','WL', 'PP', 'PP', 'AM', 'AM', 'WL', 'WL', 'PP']]
index = pd.MultiIndex.from_arrays(arrays, names=('Id', 'Name', 'Score', 'Dept'))
df = pd.DataFrame(index=index)
df = df.sort_values('Id')
df
Which yields:
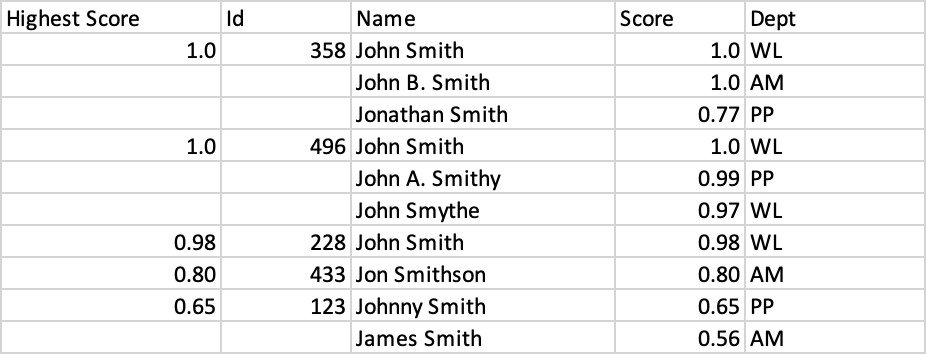
Now I need to take this a step further, and display a dataframe which:
- Gets the highest score from each group.
- Using that list of highest scores from each group, sort the groups in descending order.
- If two groups' highest scores are identical, then sort by
Idin ascending order.- Create a new column 0 called "Highest Score" which displays that highest score from that group - display each highest score value only once per group, similar to
Id.- Each group's set of scores should also be sorted in descending order.
So it would look like this:
CodePudding user response:
you can do using set_index to append the highest score per group, calculated with transform and max. then reorder_levels of the index as wanted, and sort_values, specifying ascending False or True for each level.
new_df = (
df.set_index(df.reset_index('Score').groupby('Id')
['Score'].transform(max).rename('Highest_Score'),
append=True)
.reorder_levels(['Highest_Score'] df.index.names)
.sort_values(['Highest_Score','Id','Score'], ascending=[False,True,False])
)