i have a table in big query. like this:
date(week) vendor_name value
2021-11-14 rick 8000
2021-11-14 rose 7000
2021-11-14 axel 6500
2021-11-14 boris 6000
2021-11-14 cliff 5500
2021-11-07 rose 9500
2021-11-07 axel 8750
2021-11-07 rick 4000
2021-11-07 dean 3500
2021-11-07 evan 3000
.....
The date column indicates the start date of each week. The vendor_name column shows the top 5 selling vendors that week. The value column shows the total sales amount. the top vendors of each week may be different. Expected output:
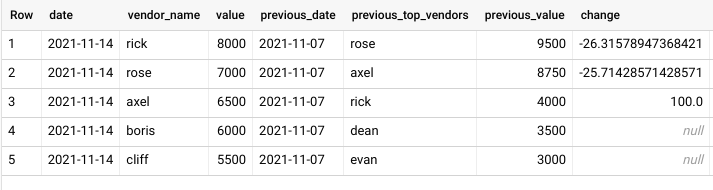
date(week) vendor_name value previous_date previous_top_vendors previous_value change
2021-11-14 rick 8000 2021-11-07 rose 9500 -%26
2021-11-14 rose 7000 2021-11-07 axel 8750 -25
2021-11-14 axel 6500 2021-11-07 rick 4000 %100
2021-11-14 boris 6000 2021-11-07 dean 3500 Null
2021-11-14 cliff 5500 2021-11-07 evan 3000 Null
After receiving the latest date, the previous week's data will arrive. for these two weeks, sellers will be compared and their percentage of change will be shown in the column called change.
Note: The rank of vendors may change every week. A new vendor can be ranked (In this case, it should appear as Null in the "change" column)
I tried this:
SELECT * FROM (select*from `table.top20_vendor` where date = '2021-11-14'),
(select date as previous_date, vendor_name as previous_top_vendors,value as previous_value
from `table.top20_vendor` where date ='2021-11-07')
but the output not true:
date(week) vendor_name value previous_date previous_top_vendors previous_value
2021-11-14 rick 8000 2021-11-07 rose 9500
2021-11-14 rick 8000 2021-11-07 axel 8750
2021-11-14 rick 8000 2021-11-07 rick 4000
2021-11-14 rick 8000 2021-11-07 dean 3500
2021-11-14 rick 8000 2021-11-07 evan 3000
also, I have no idea how to calculate the "change" column
CodePudding user response:
I still do not understand your logic you have for change in terms of which records you're comparing against, but this should get you most of the way there in terms of comparing the vendors and their values between weeks:
with sample_data as (
select '2021-11-14' as week, 'rick' as vendor_name, 8000 as value UNION ALL
select '2021-11-14' as week, 'rose' as vendor_name, 7000 as value UNION ALL
select '2021-11-14' as week, 'axel' as vendor_name, 6500 as value UNION ALL
select '2021-11-14' as week, 'boris' as vendor_name, 6000 as value UNION ALL
select '2021-11-14' as week, 'cliff' as vendor_name, 5500 as value UNION ALL
select '2021-11-07' as week, 'rose' as vendor_name, 9500 as value UNION ALL
select '2021-11-07' as week, 'axel' as vendor_name, 8750 as value UNION ALL
select '2021-11-07' as week, 'rick' as vendor_name, 4000 as value UNION ALL
select '2021-11-07' as week, 'dean' as vendor_name, 3500 as value UNION ALL
select '2021-11-07' as week, 'evan' as vendor_name, 3000 as value
)
,
ranked_data as (
select dense_rank() over (order by week desc) week_rank
, rank() over (partition by week order by value) vendor_rank
, *
from sample_data
)
select curr_week.week
, curr_week.vendor_name
, curr_week.value
, prev_week.week as previous_week
, prev_week.vendor_name as previous_top_vendors
, prev_week.value as previous_value
,
from ranked_data curr_week
left join ranked_data prev_week
on curr_week.vendor_rank=prev_week.vendor_rank
and prev_week.week_rank=2
where curr_week.week_rank=1
order by 3 desc
Ultimately I think you'll need a lead or lag depending on the calculation in the middle step. If you can elaborate a bit more I may be able to add the component in for change.
CodePudding user response:
What I did first was to get the top 5 values of the desired week, and I used the following query:
select * from
(
select date, vendor_name, value , row_number() over(partition by date order by value desc) as rn
from `project.dataset.table`
)A
where rn<=5 and date='2021-11-14'
Then, what needs to be done is to make the change of the values. For that, you need to use a percentage formula and join these weeks’ value by the name of the vendors.
SELECT prev_week.rn,((curr_week.value-prev_week.value)/prev_week.value)*100 as change FROM curr_week right join prev_week on curr_week.vendor_name = prev_week.vendor_name
Consider the approach below:
with curr_week as(
select * from
(
select date, vendor_name, value , row_number() over(partition by date order by value desc) as rn
from `project.dataset.table`
)A
where rn<=5 and date='2021-11-14'
),
prev_week as (
select * from
(
select date, vendor_name, value , row_number() over(partition by date order by value desc) as rn
from `project.dataset.table`
)A
where rn<=5 and date='2021-11-07'
),
changes as(
SELECT prev_week.rn,((curr_week.value-prev_week.value)/prev_week.value)*100 as change FROM curr_week right join prev_week on curr_week.vendor_name = prev_week.vendor_name
)
select curr_week.date,
curr_week.vendor_name,
curr_week.value,
prev_week.date as previous_date,
prev_week.vendor_name as previous_top_vendors,
prev_week.value as previous_value,
changes.change
from curr_week left join prev_week on curr_week.rn = prev_week.rn
left join changes on prev_week.rn = changes.rn
The results I get are as follows: