I'm using ANTLR4 to lex and parse a string. The string is this:
alpha at 3
The grammar is as such:
access: IDENTIFIER 'at' INT;
IDENTIFIER: [A-Za-z] ;
INT: '-'? ([1-9][0-9]* | [0-9]);
However, this ANTLR gives me line 1:6 mismatched input 'at' expecting 'at'. I've found that it is because IDENTIFIER is a superset of 'at', as seen in 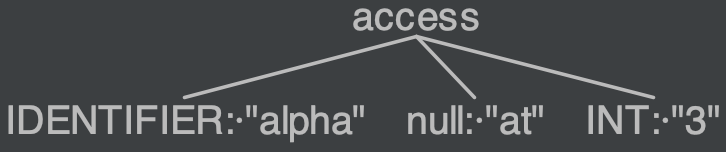
The second:
access: identifier AT INT;
identifier: NAME | ~AT;
NAME: [A-Za-z] ;
INT: '-'? ([1-9][0-9]* | [0-9]);
AT: 'at';
produces indeed the error. This is because NAME and AT both match the text "at". And because NAME is defined before AT, a NAME token will be created.
Always be careful with such overlapping tokens: place keywords always above NAME or identifier tokens:
access: IDENTIFIER AT INT;
AT: 'at';
IDENTIFIER: [A-Za-z] ;
INT: '-'? ([1-9][0-9]* | [0-9]);
Note that ANTLR will only look at which rule is defined first when rules match the same amount of characters. So for input like "atat", an IDENTIFIER will be created (not 2 AT tokens!).